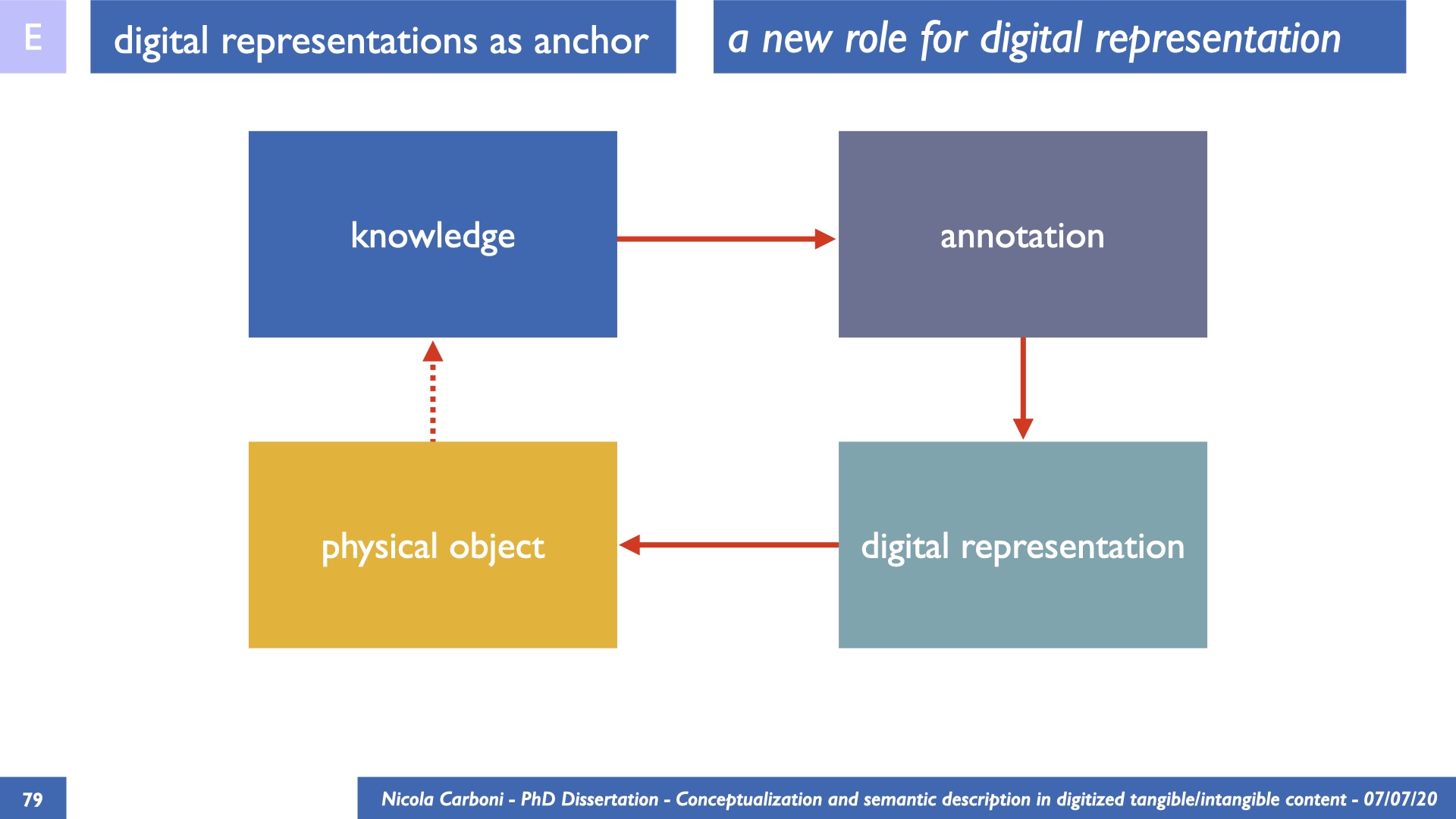



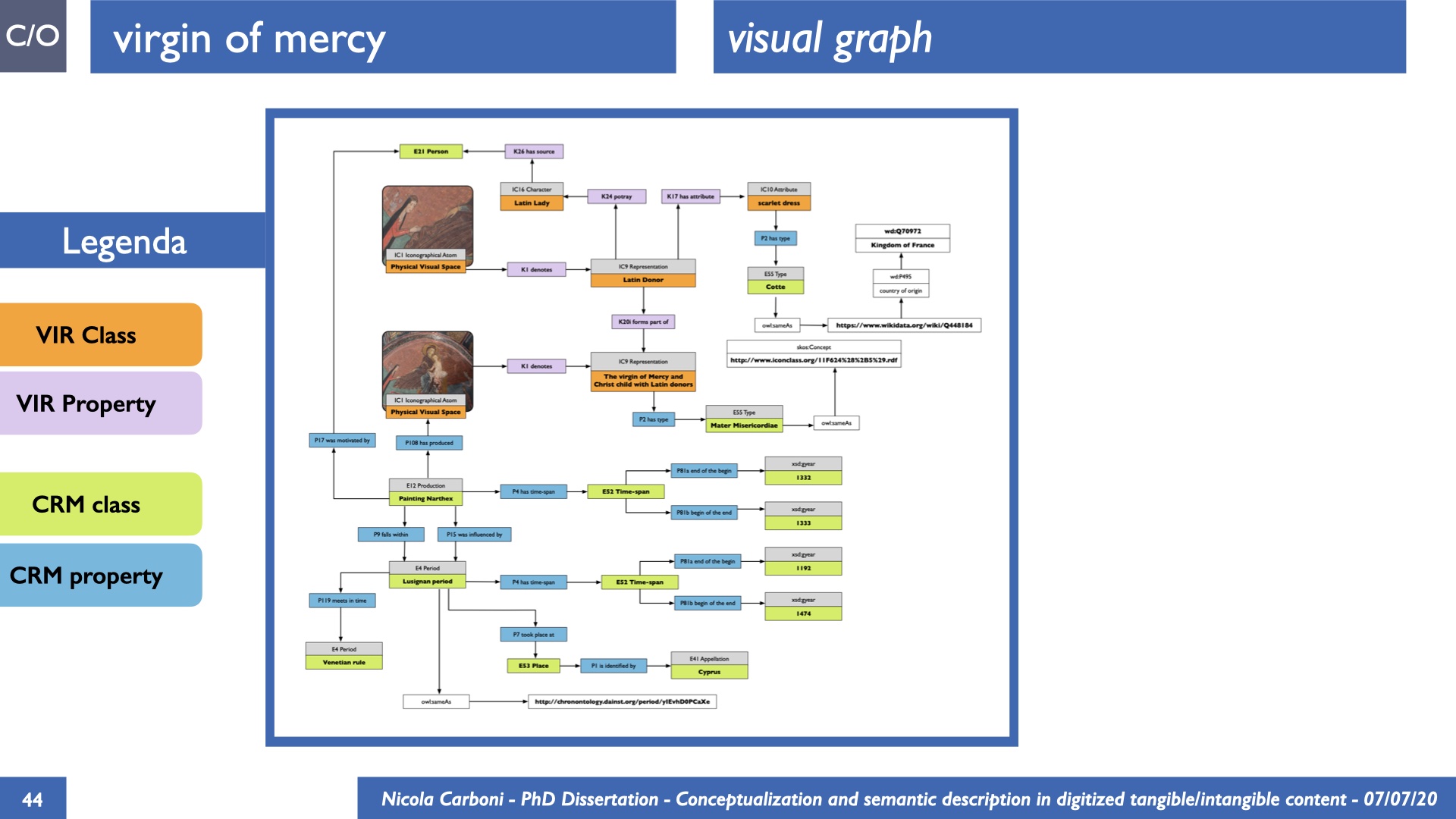
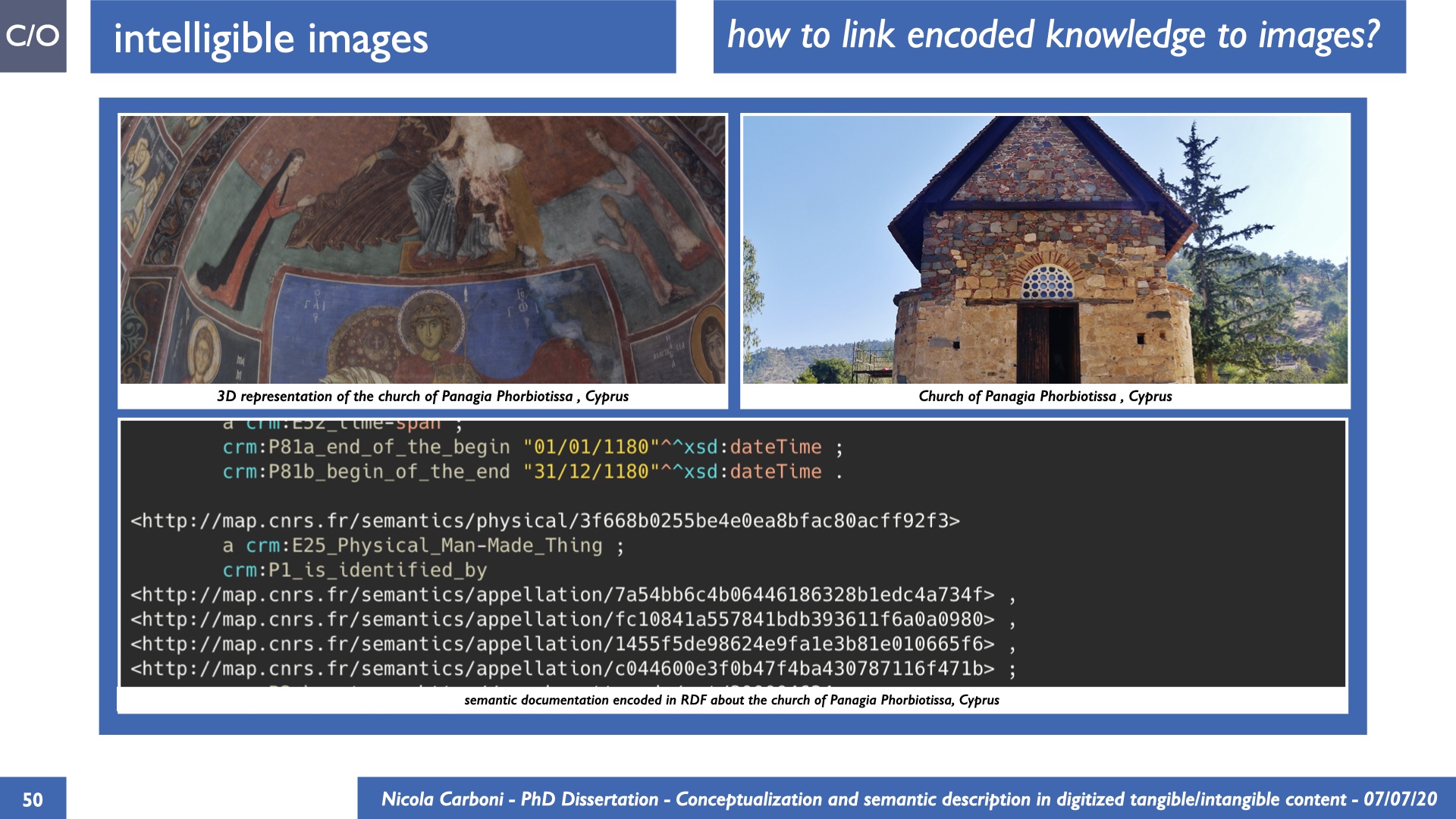

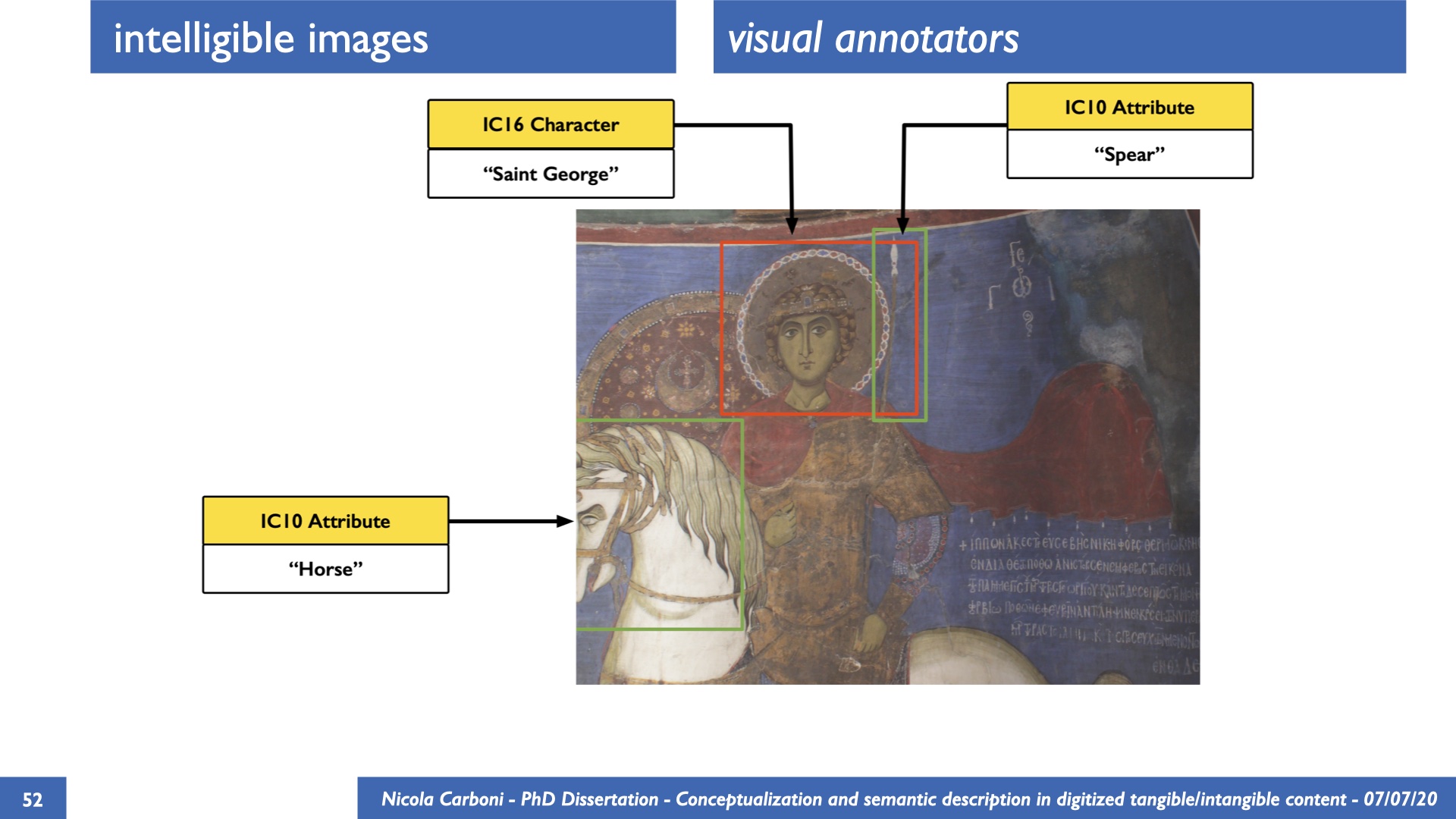

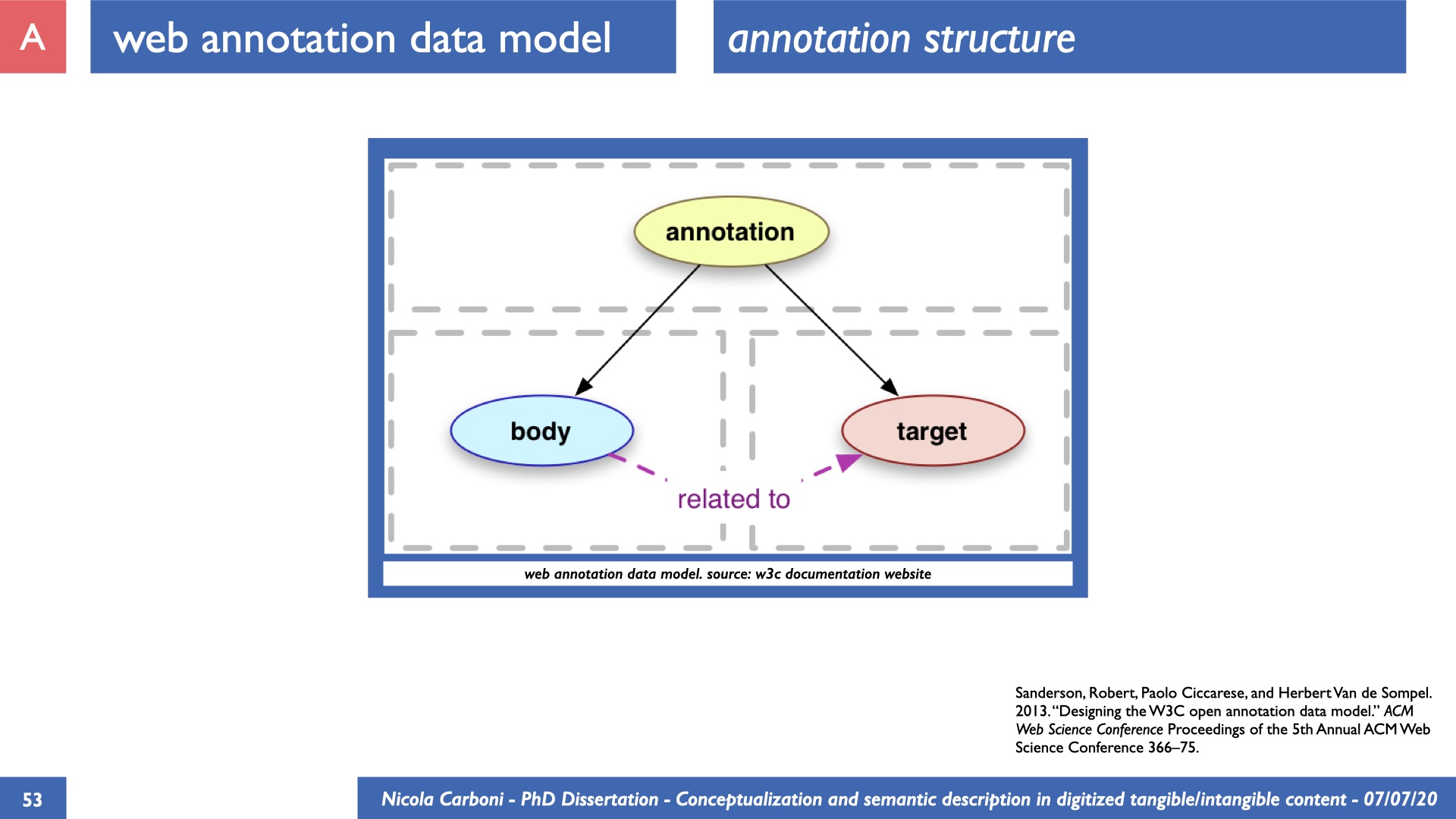
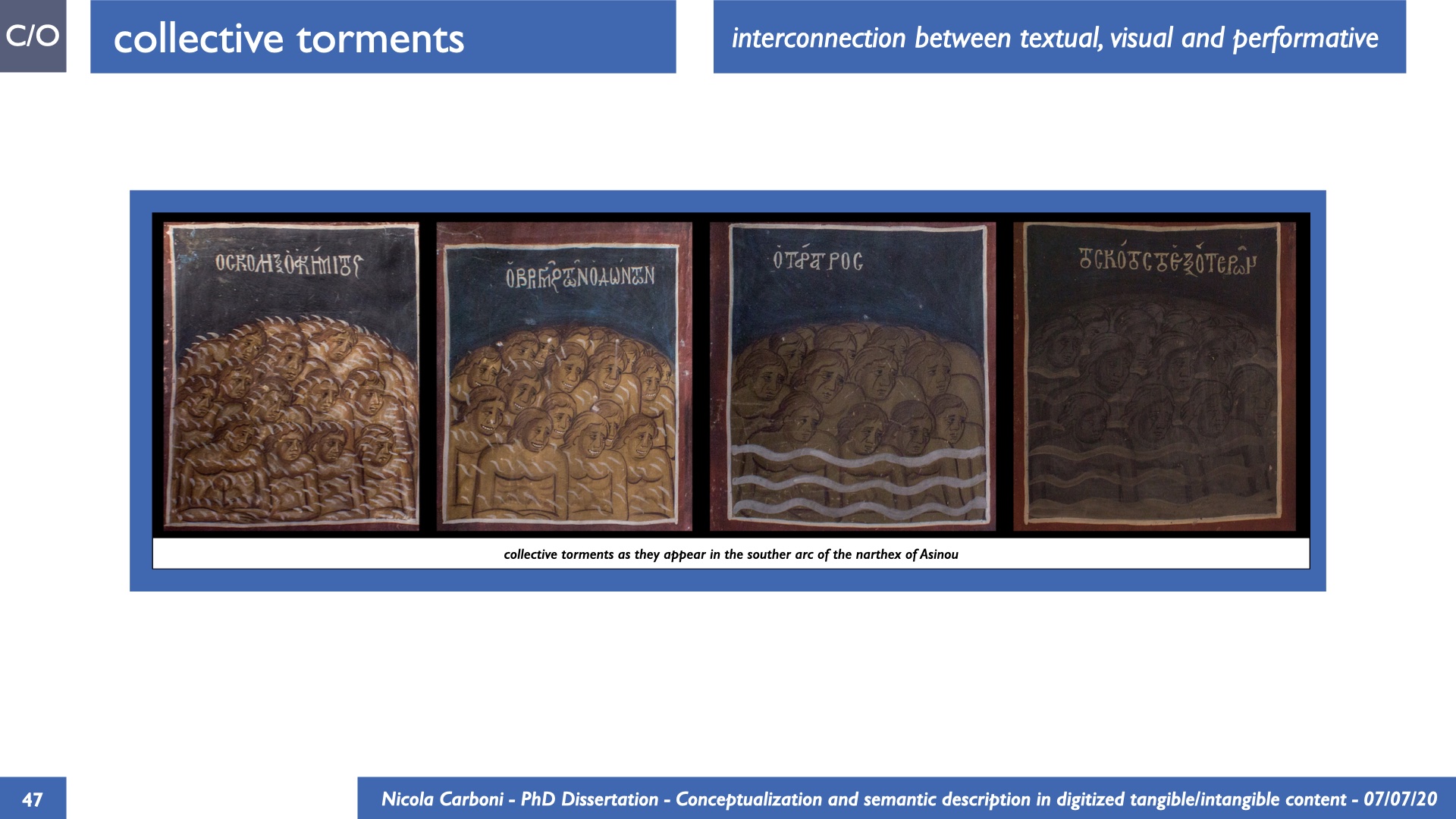

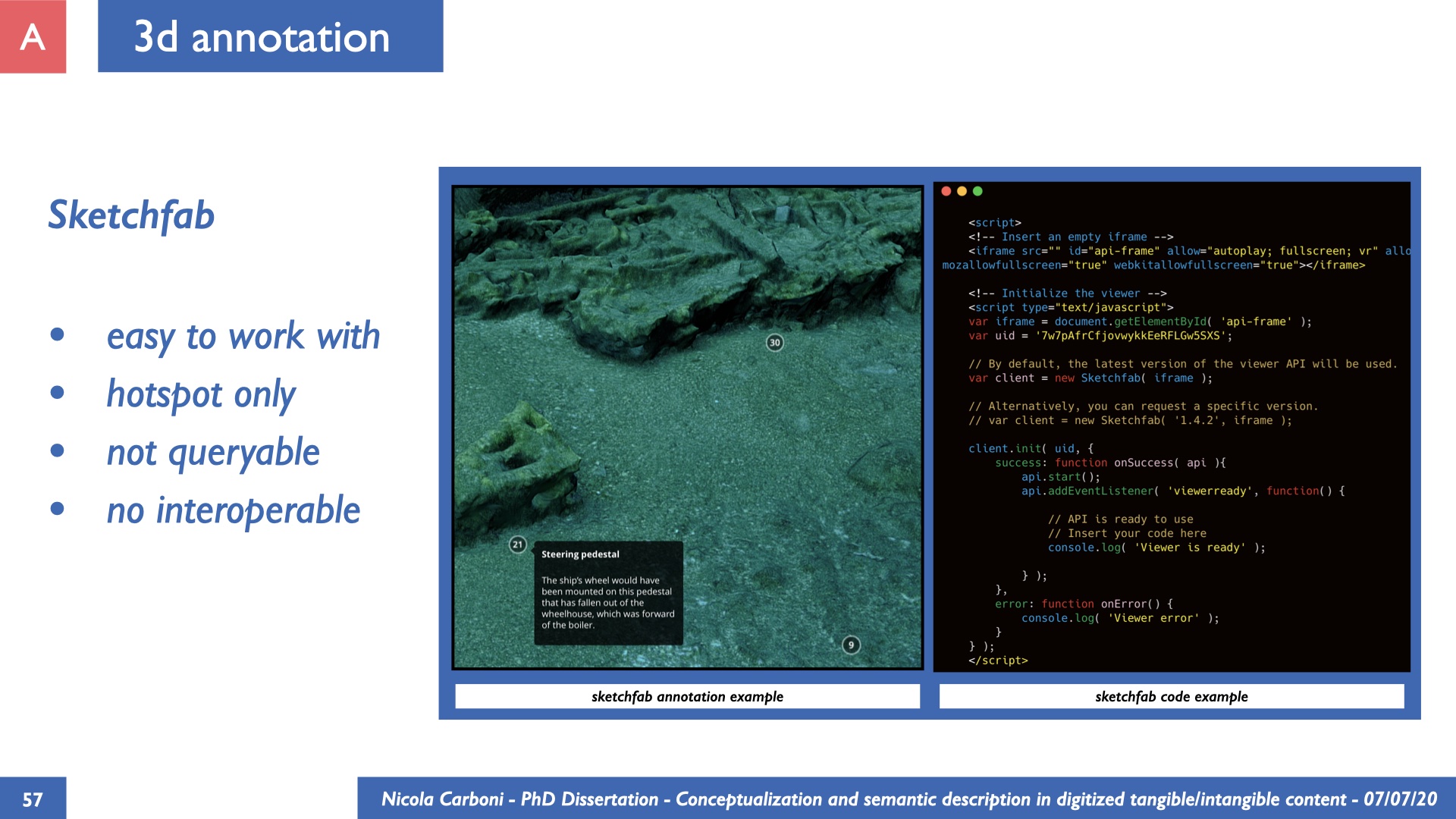
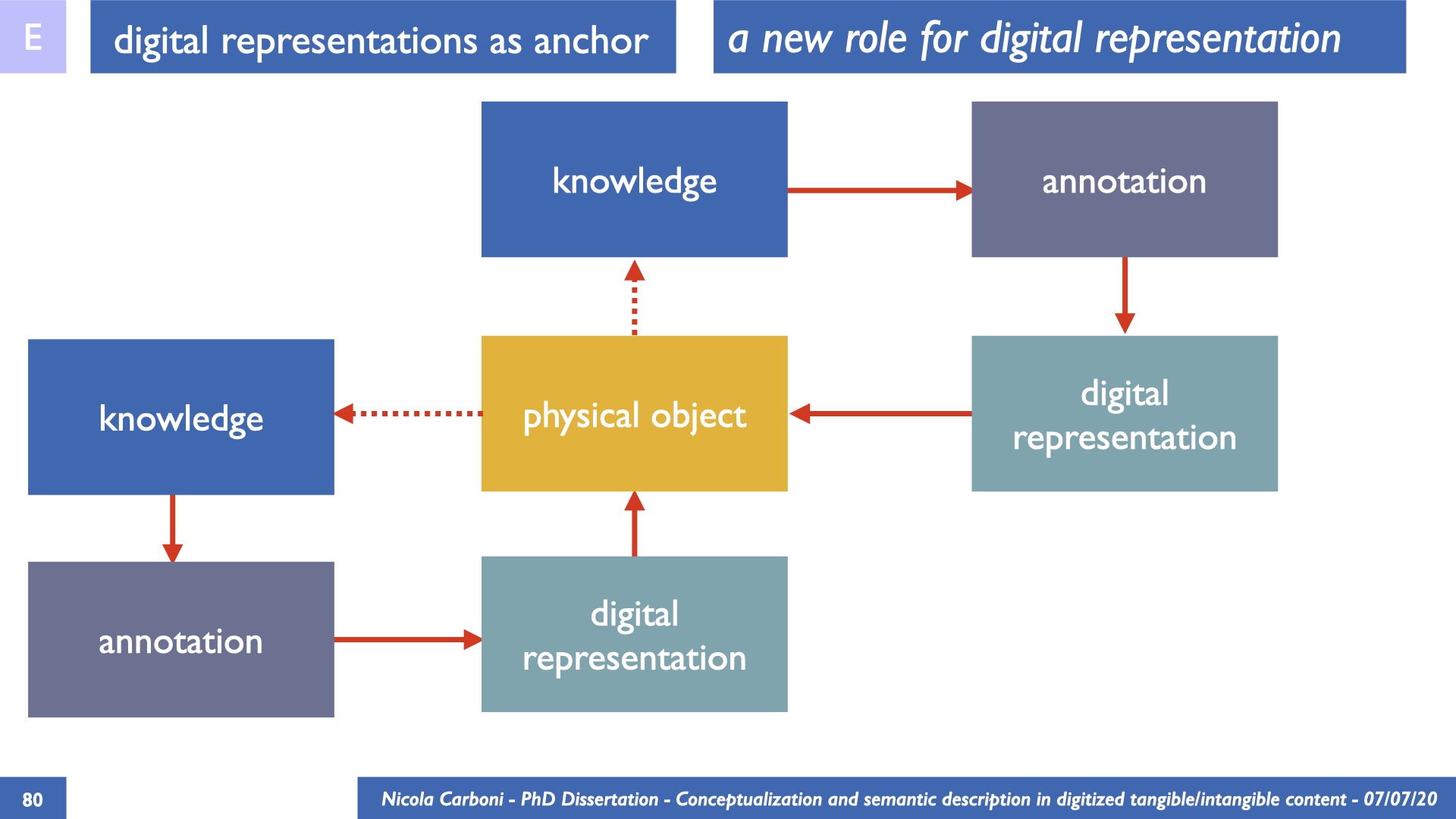
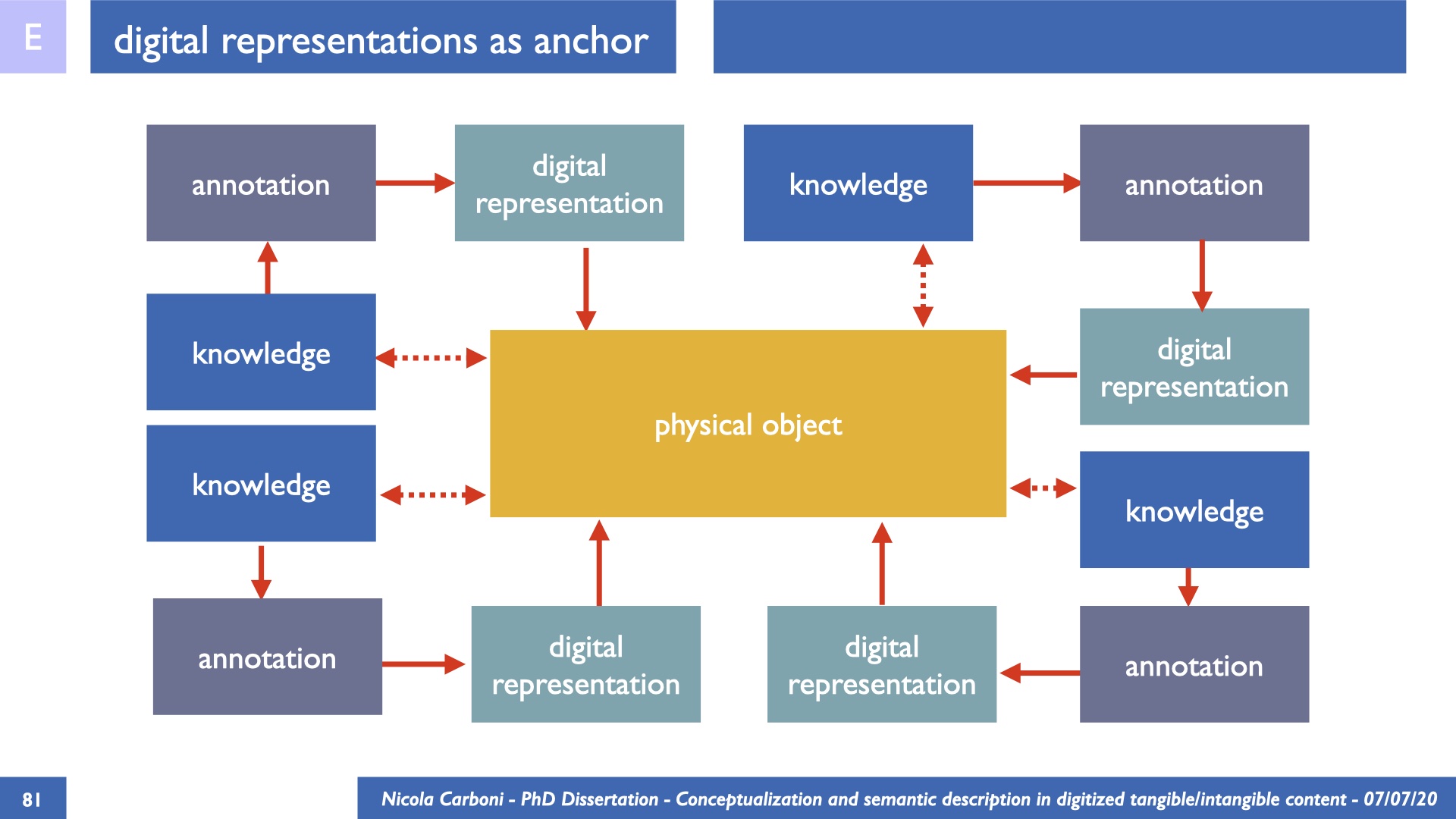

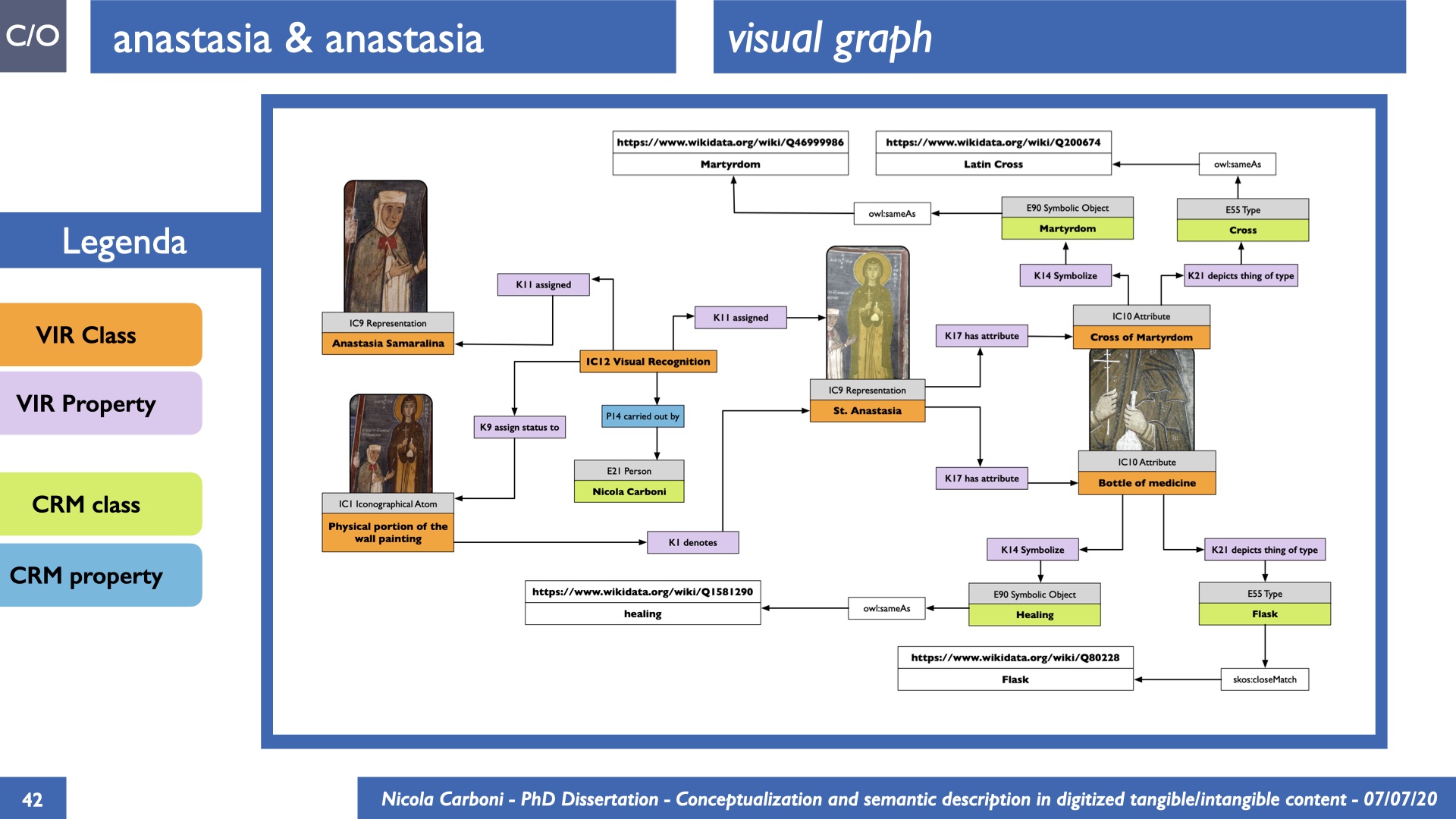
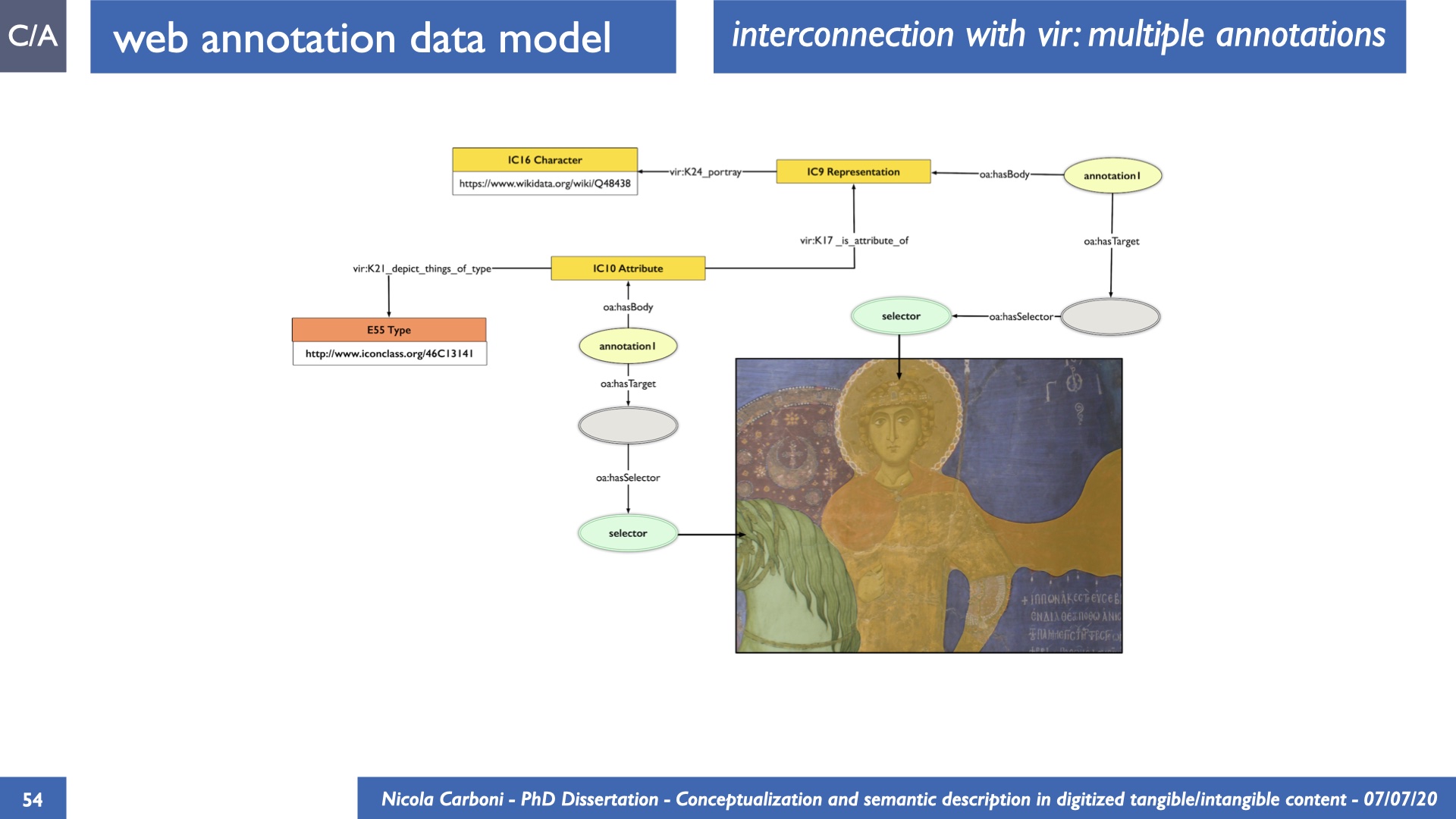
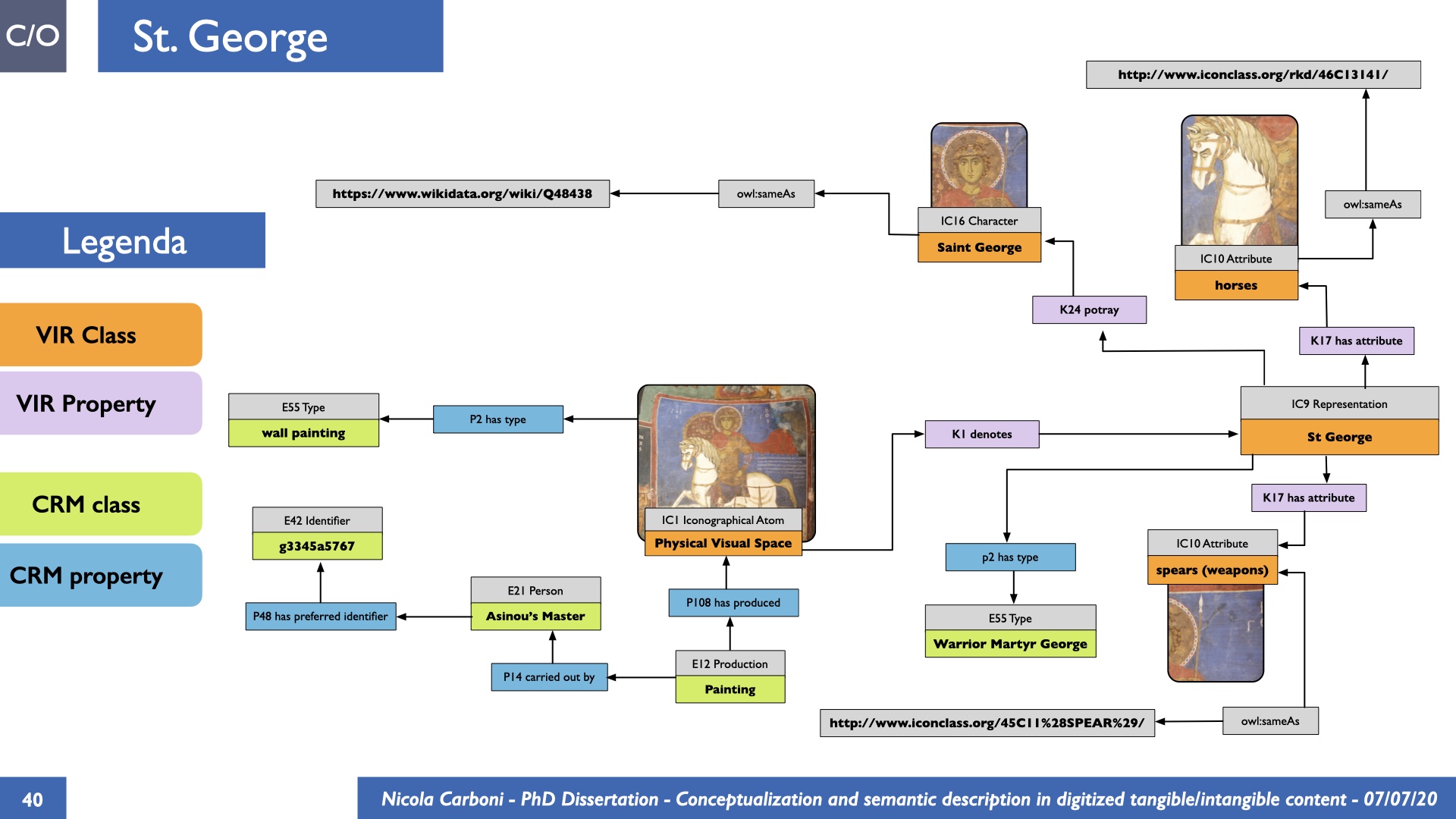
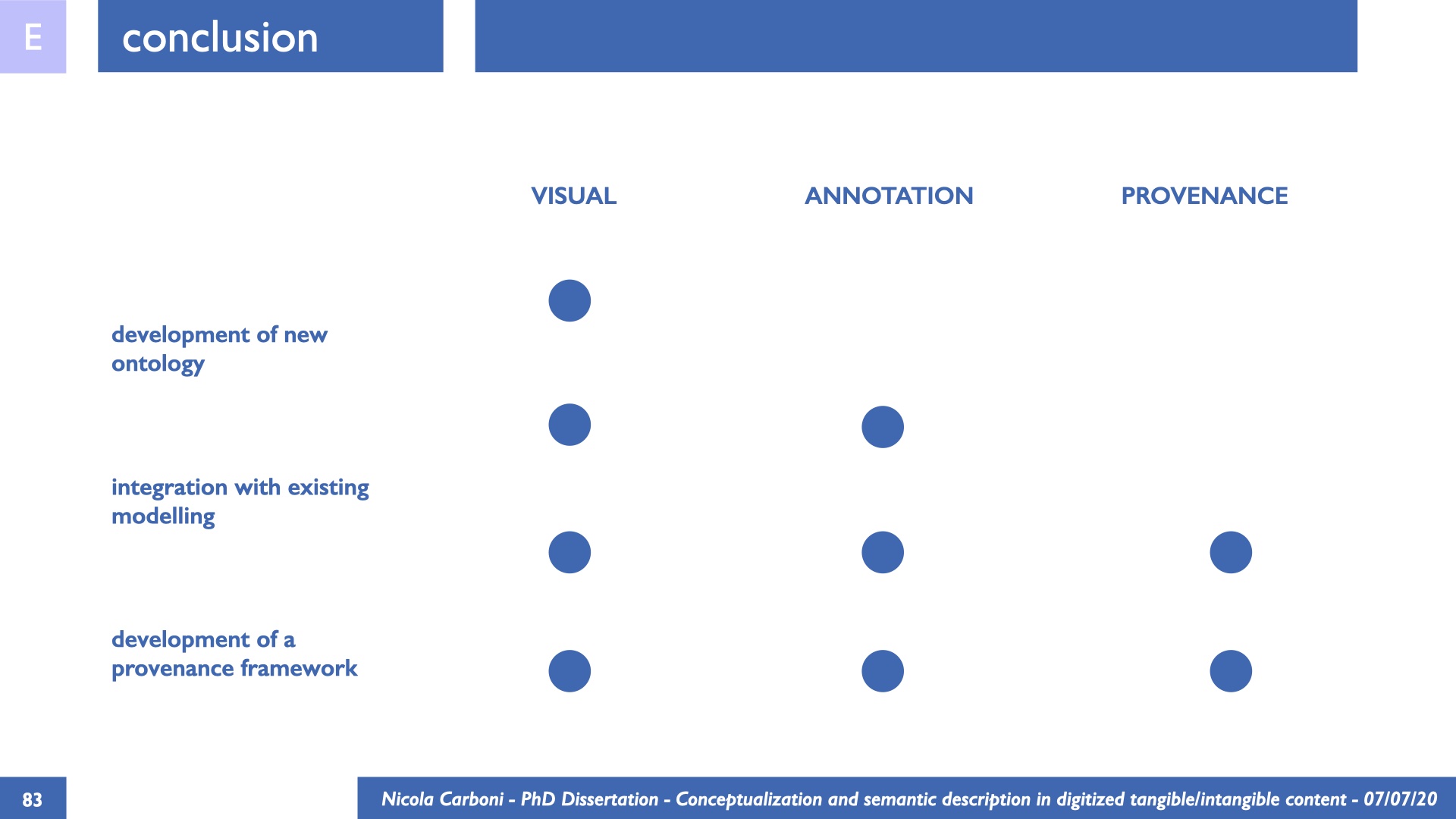
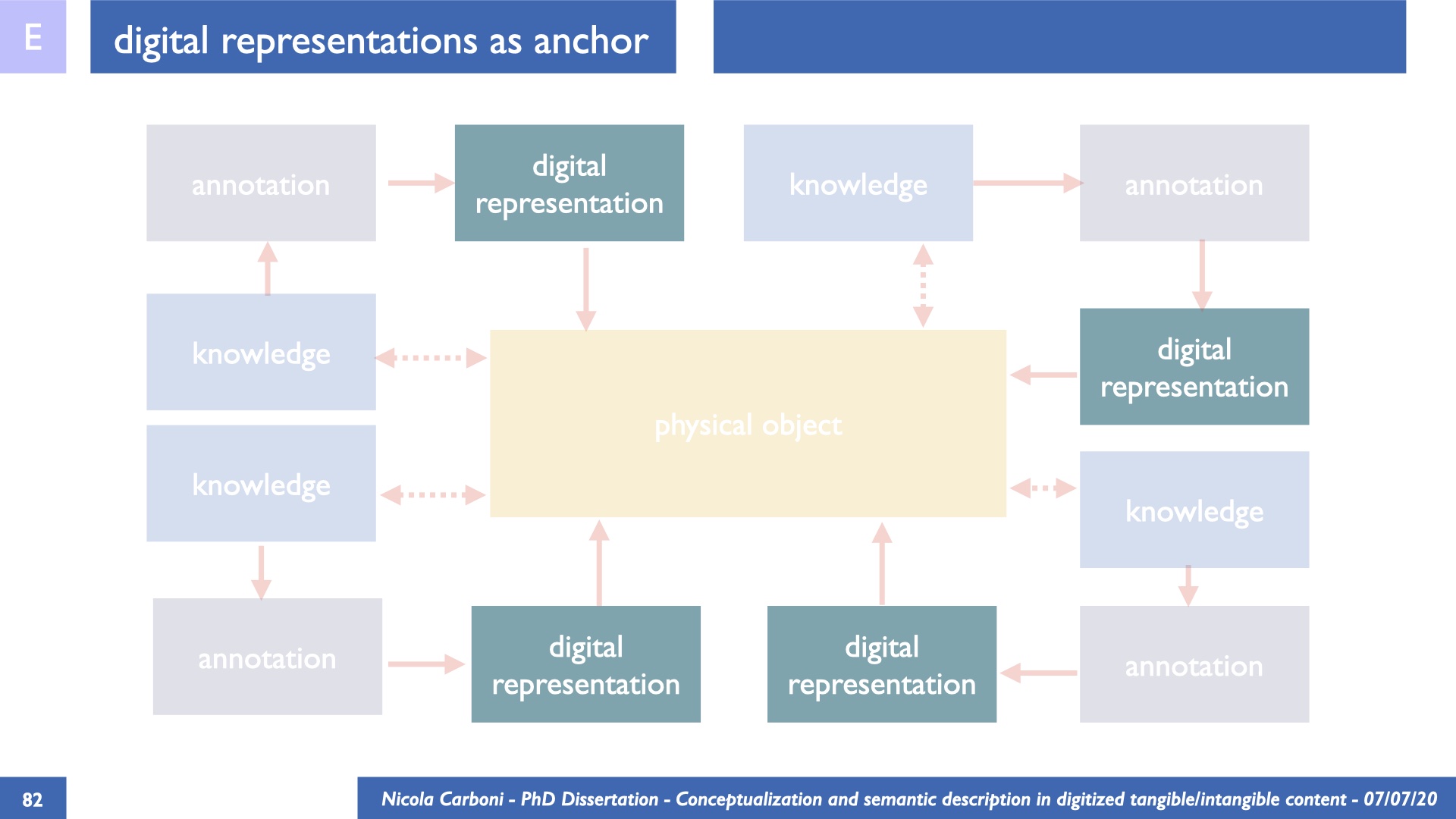
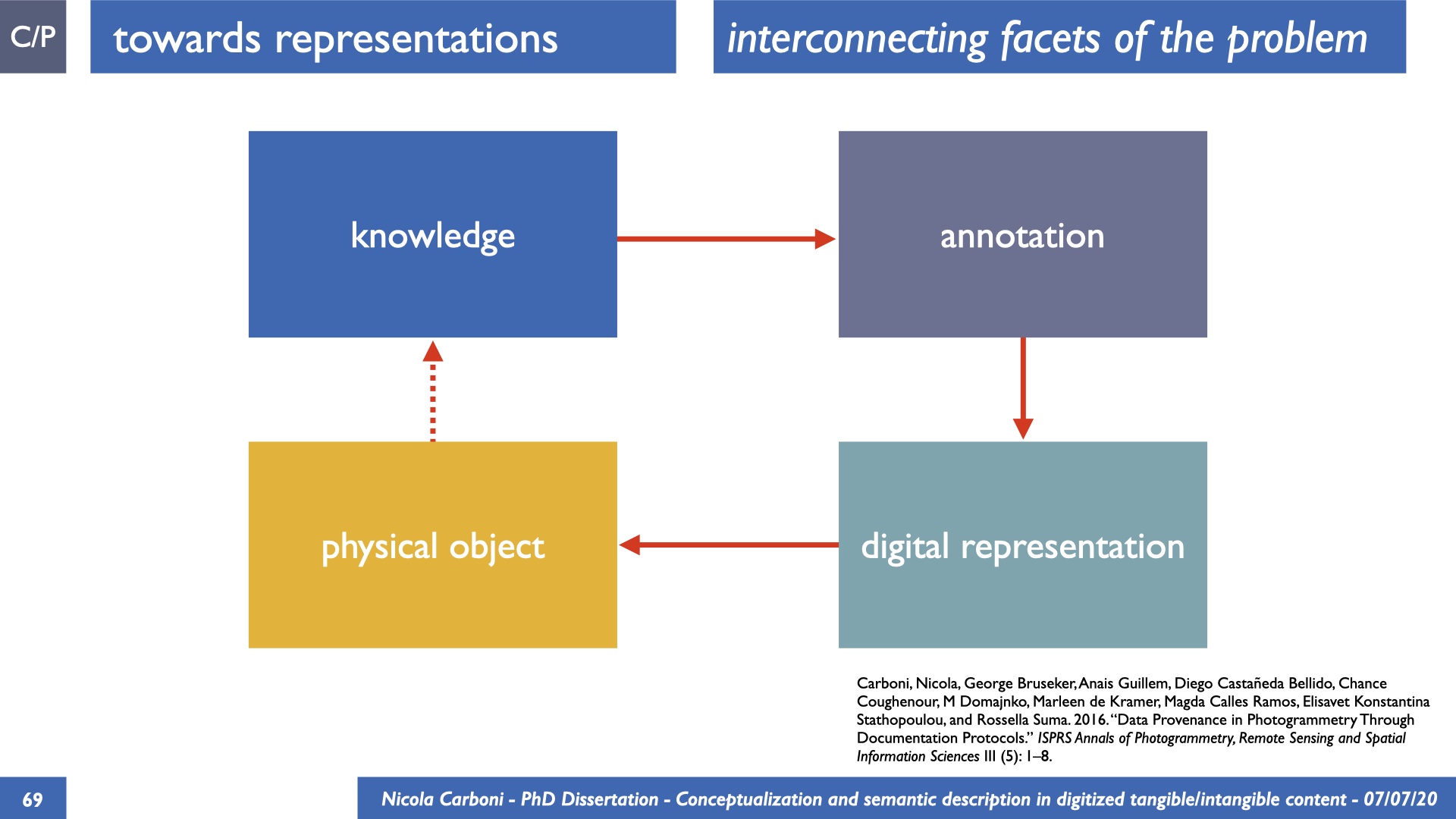


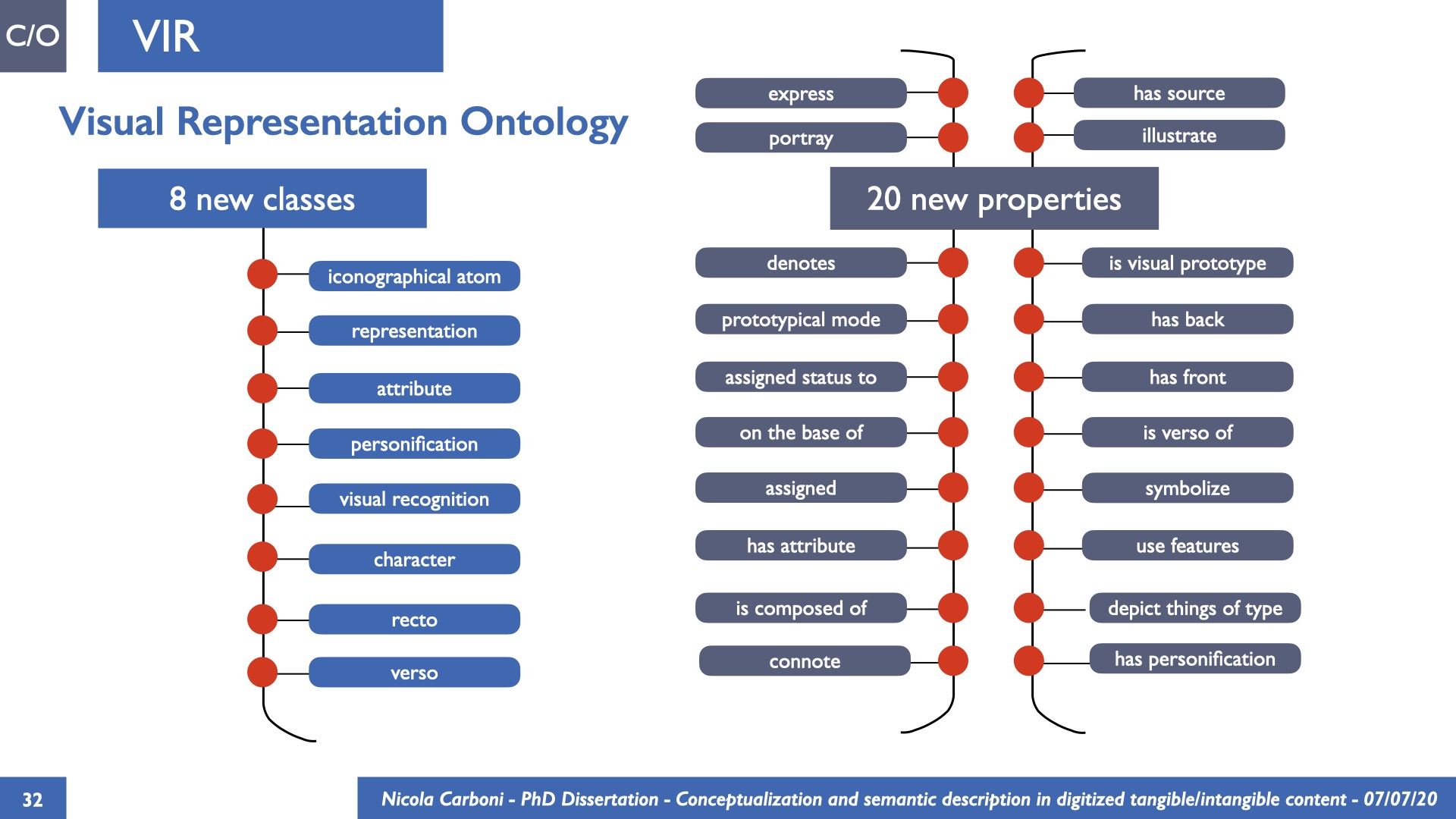
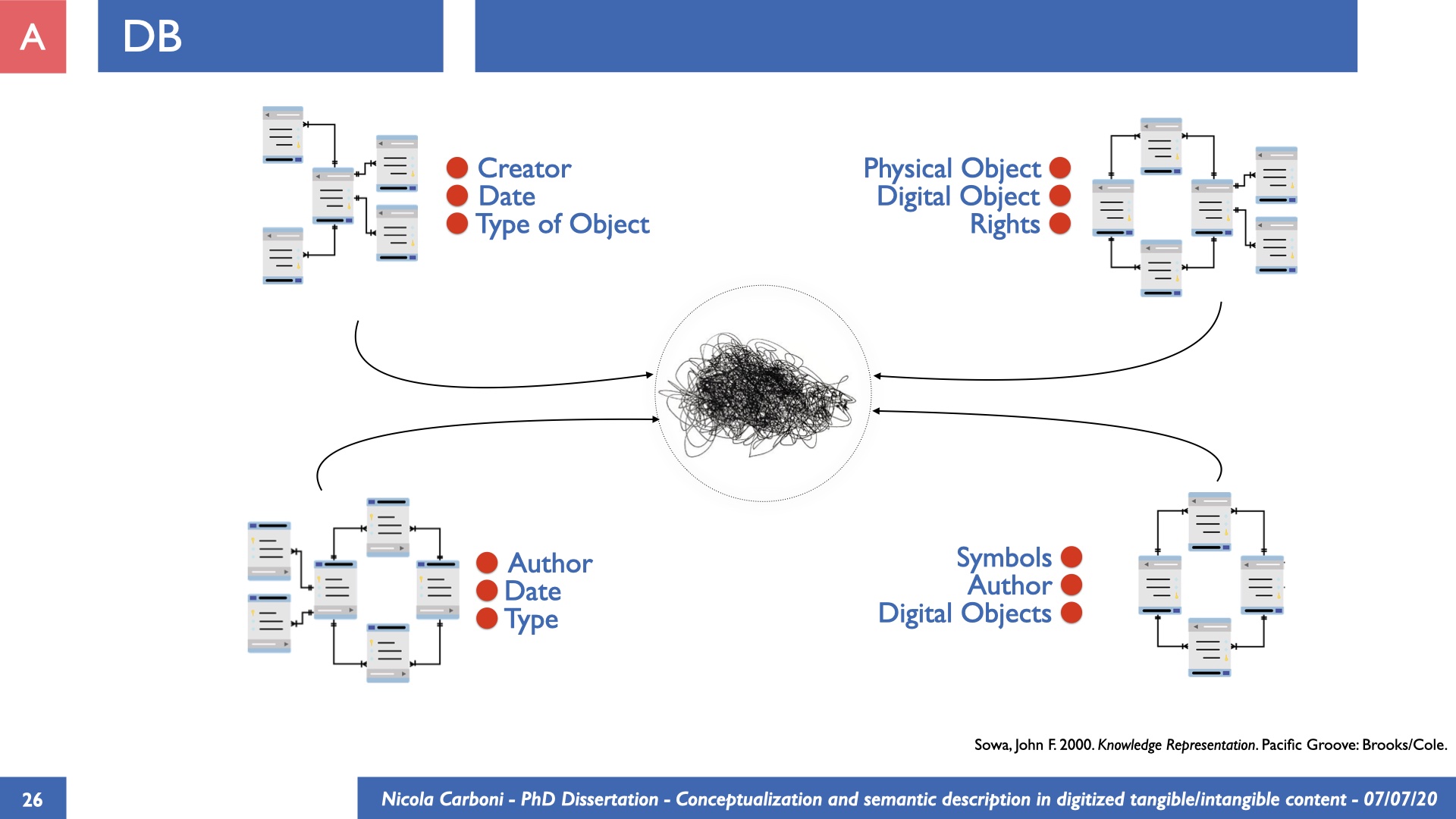
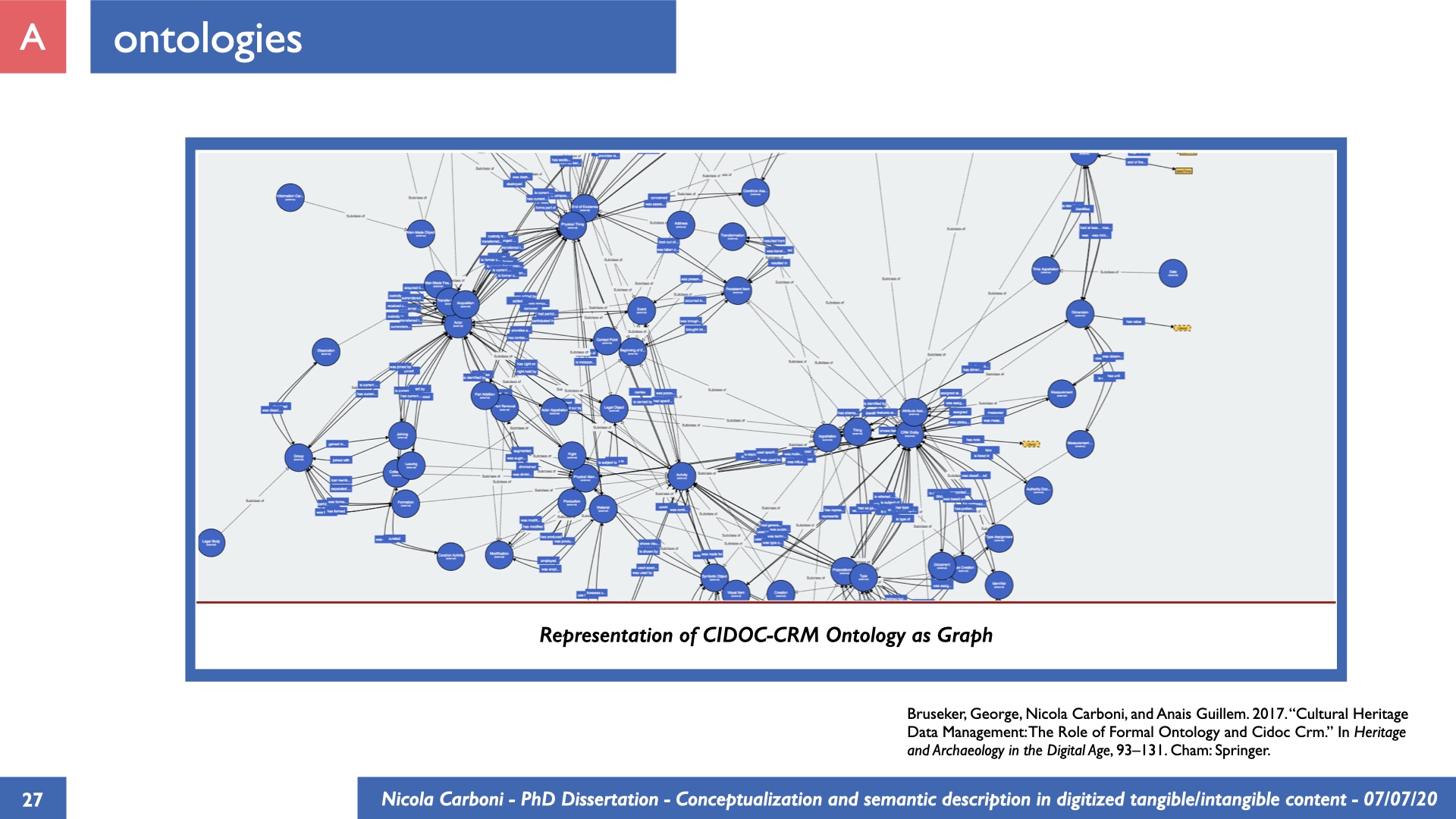
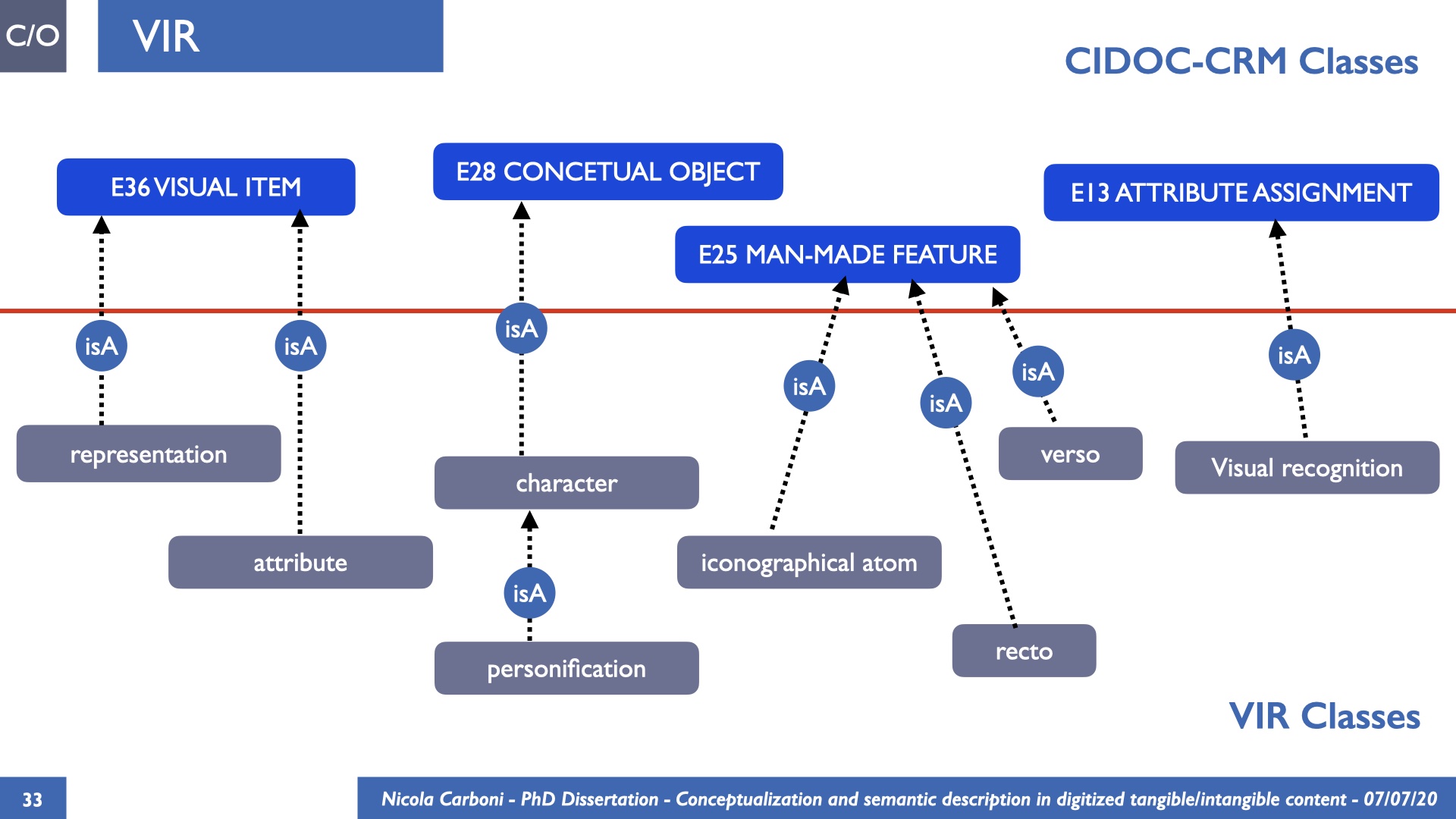

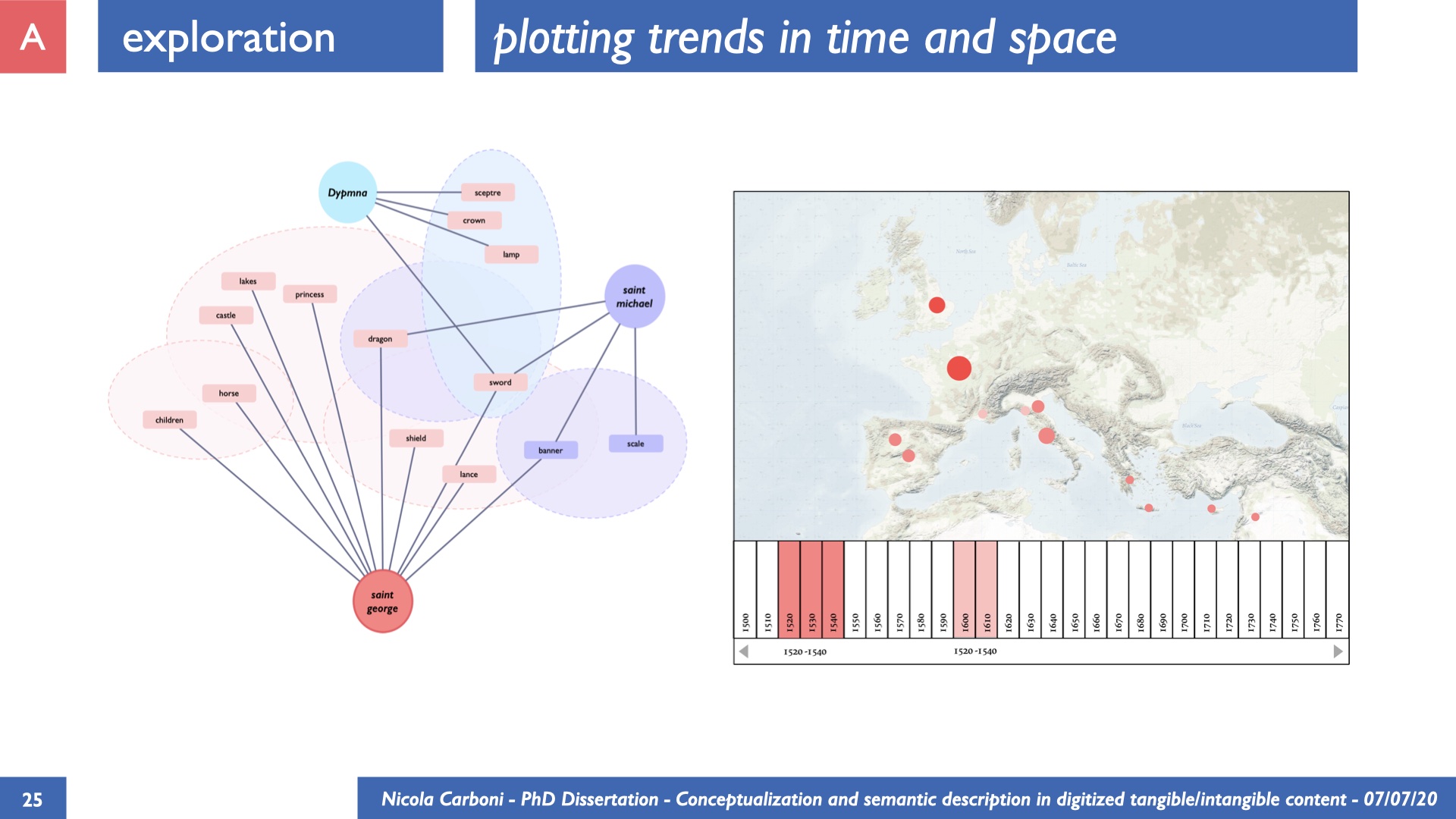
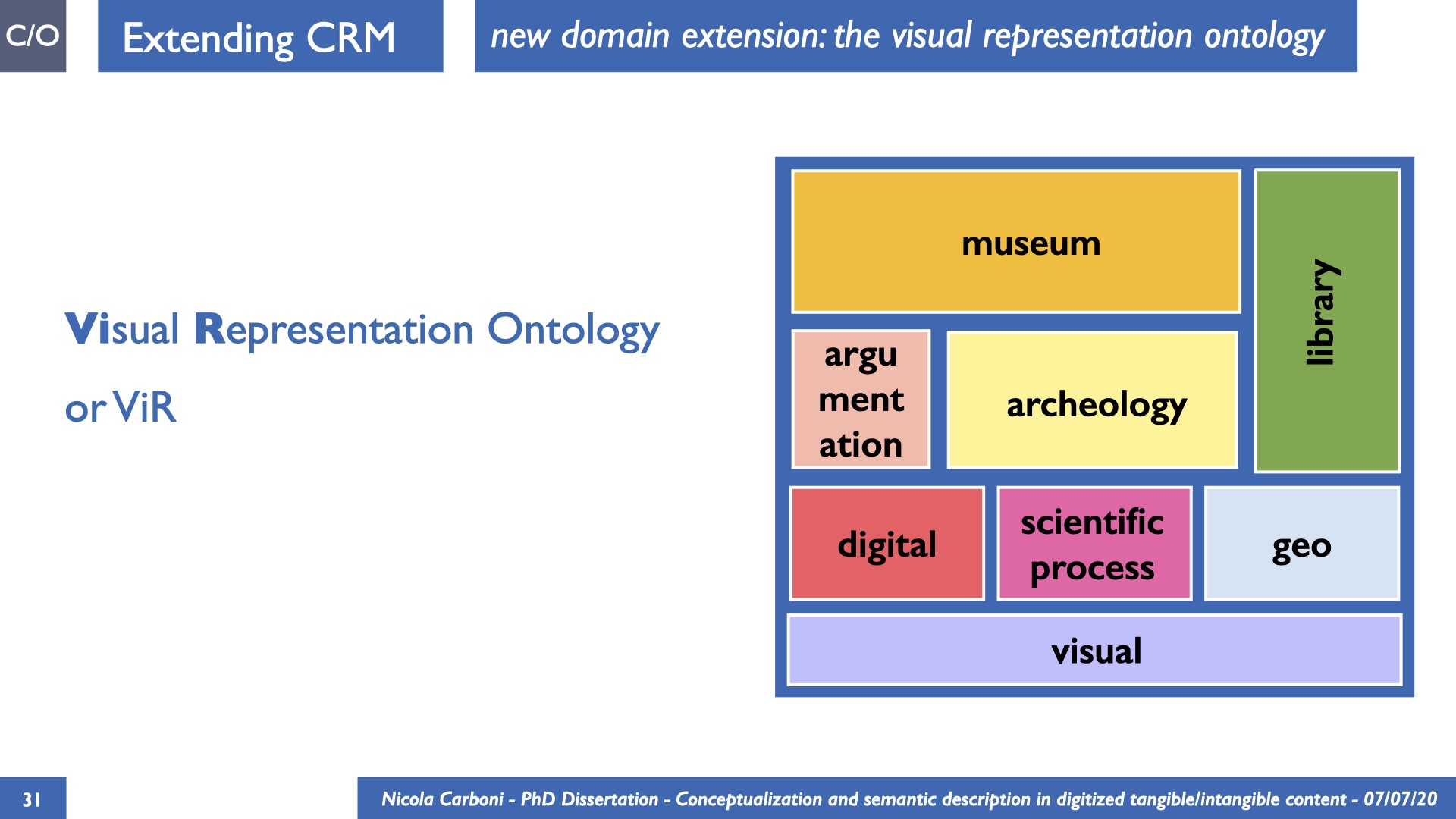
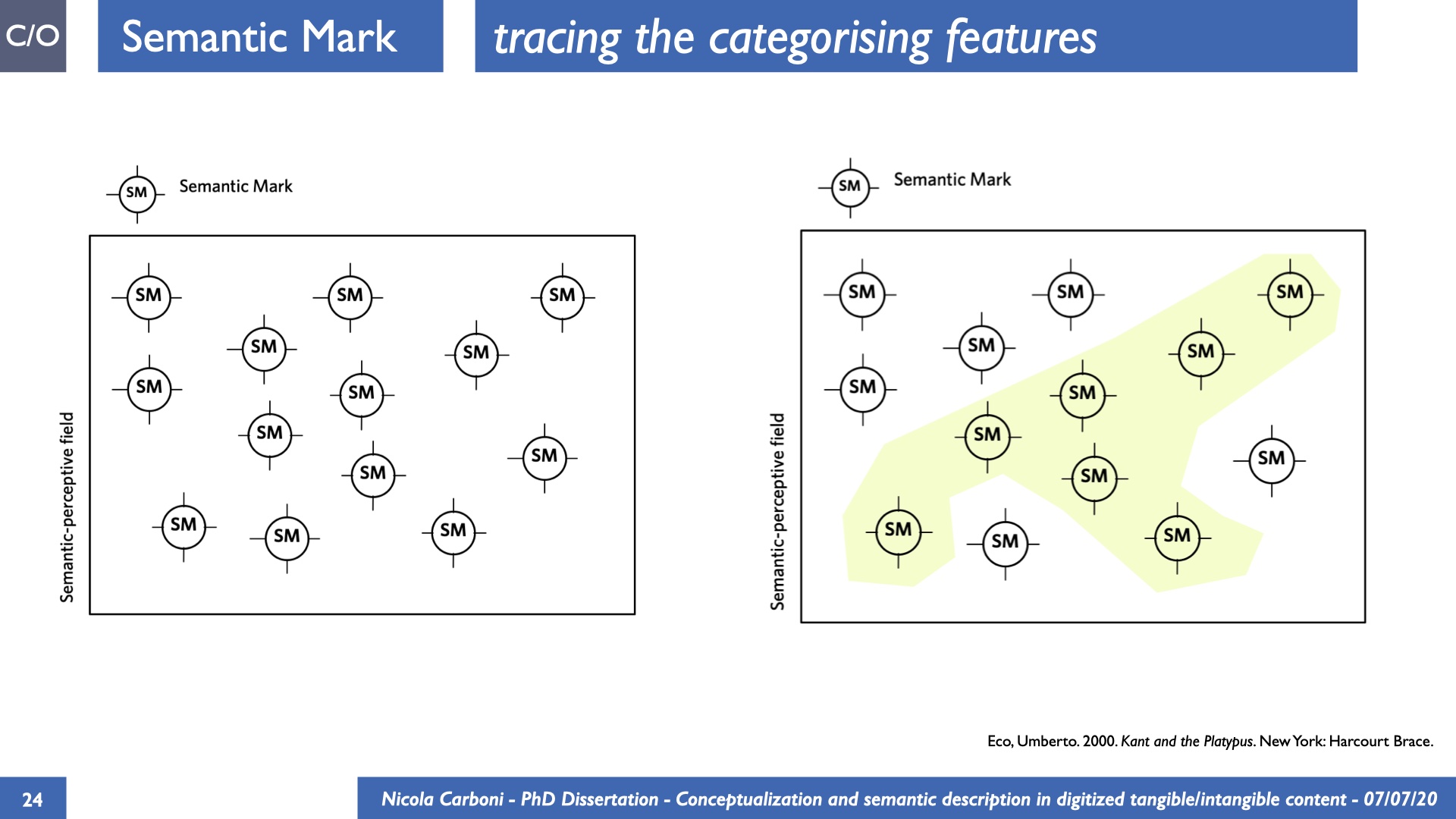

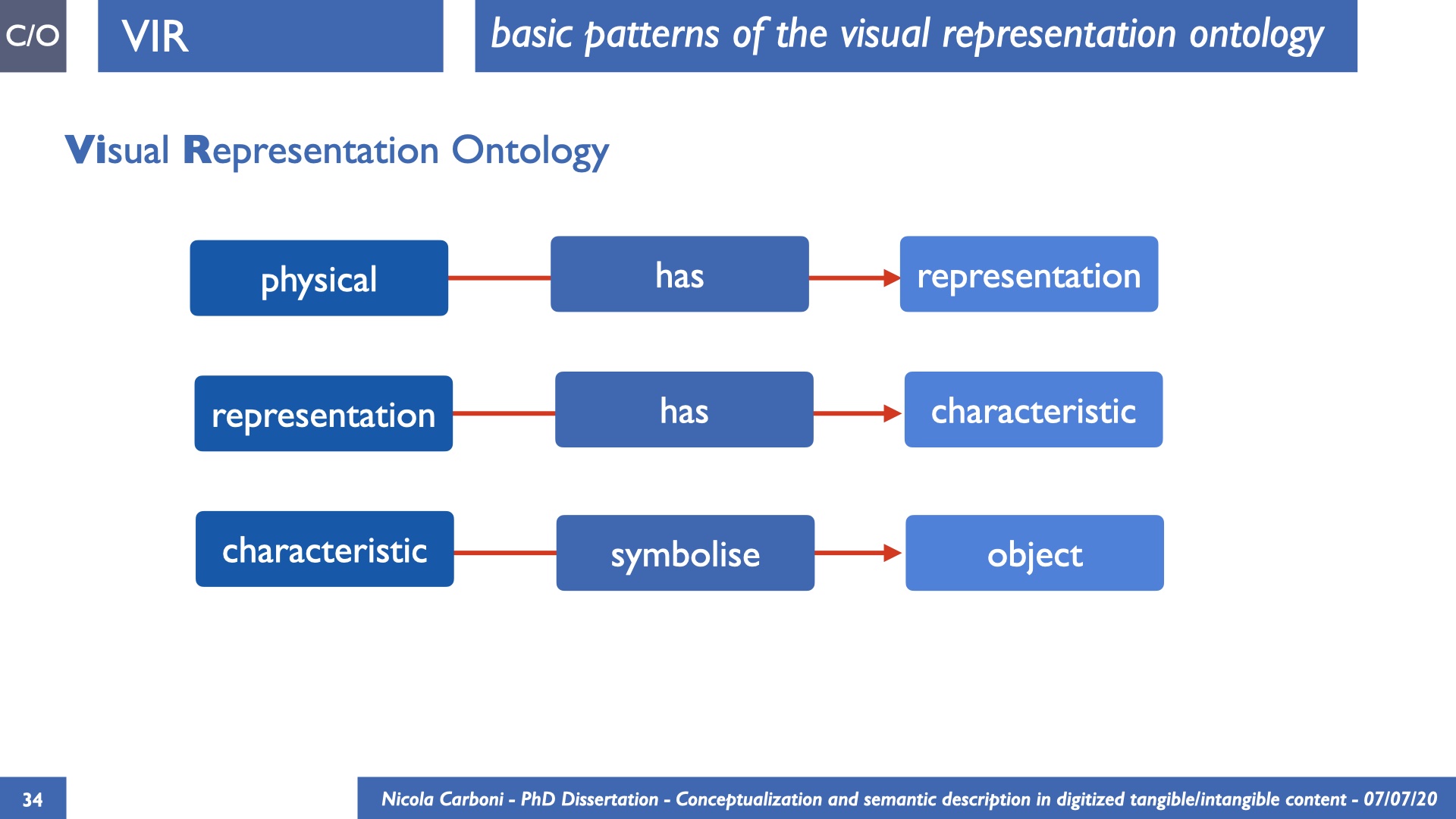




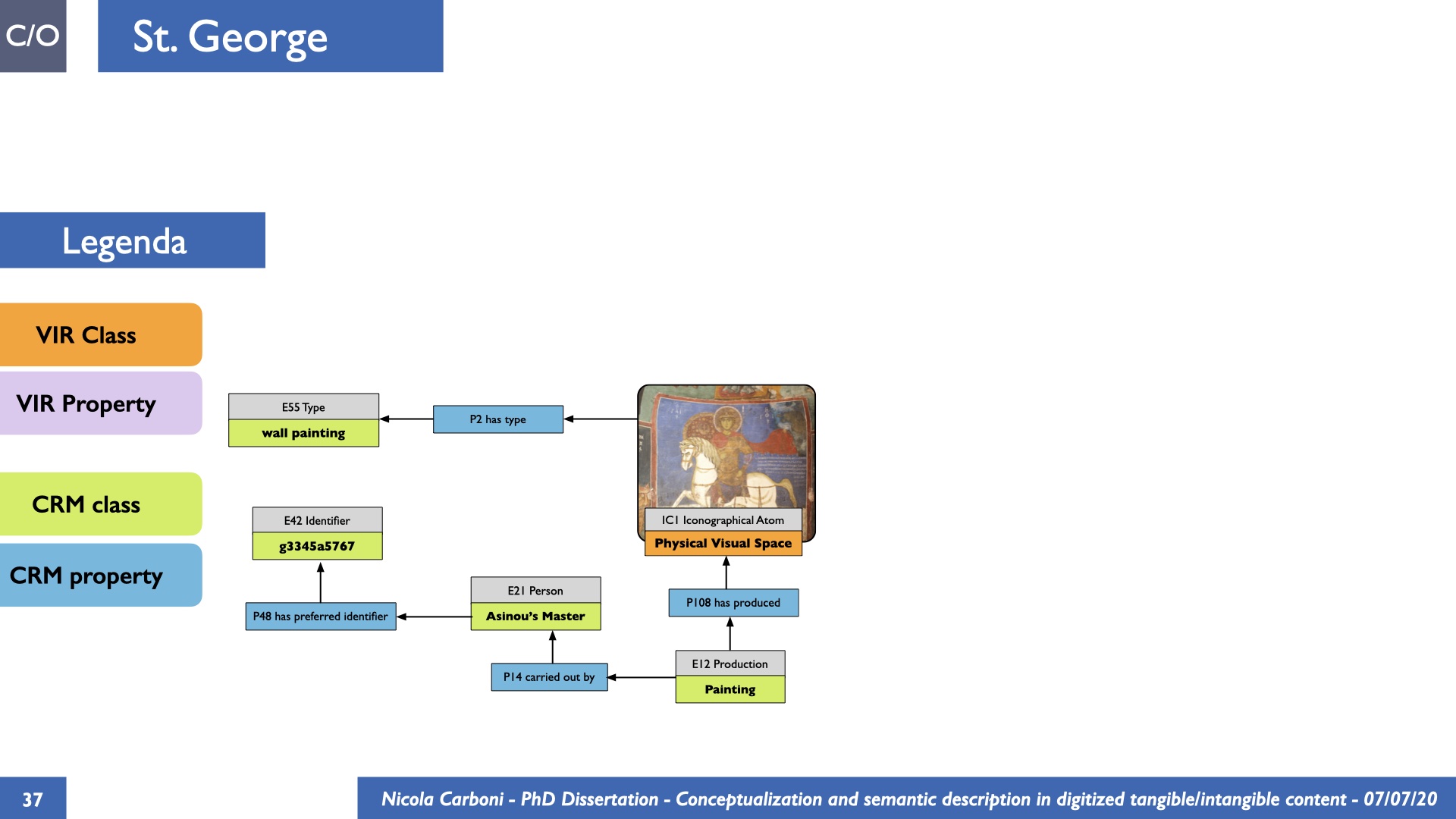


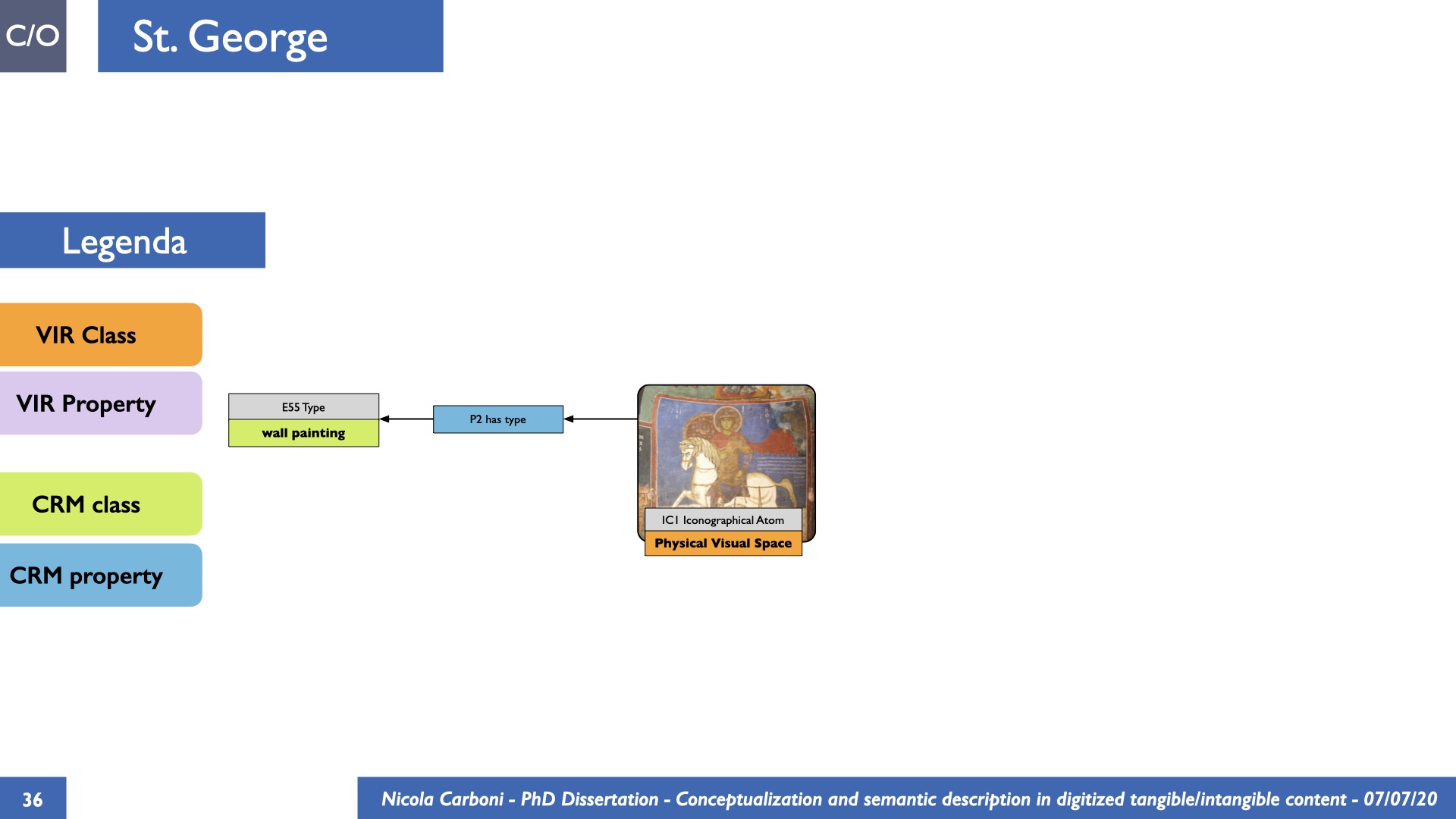




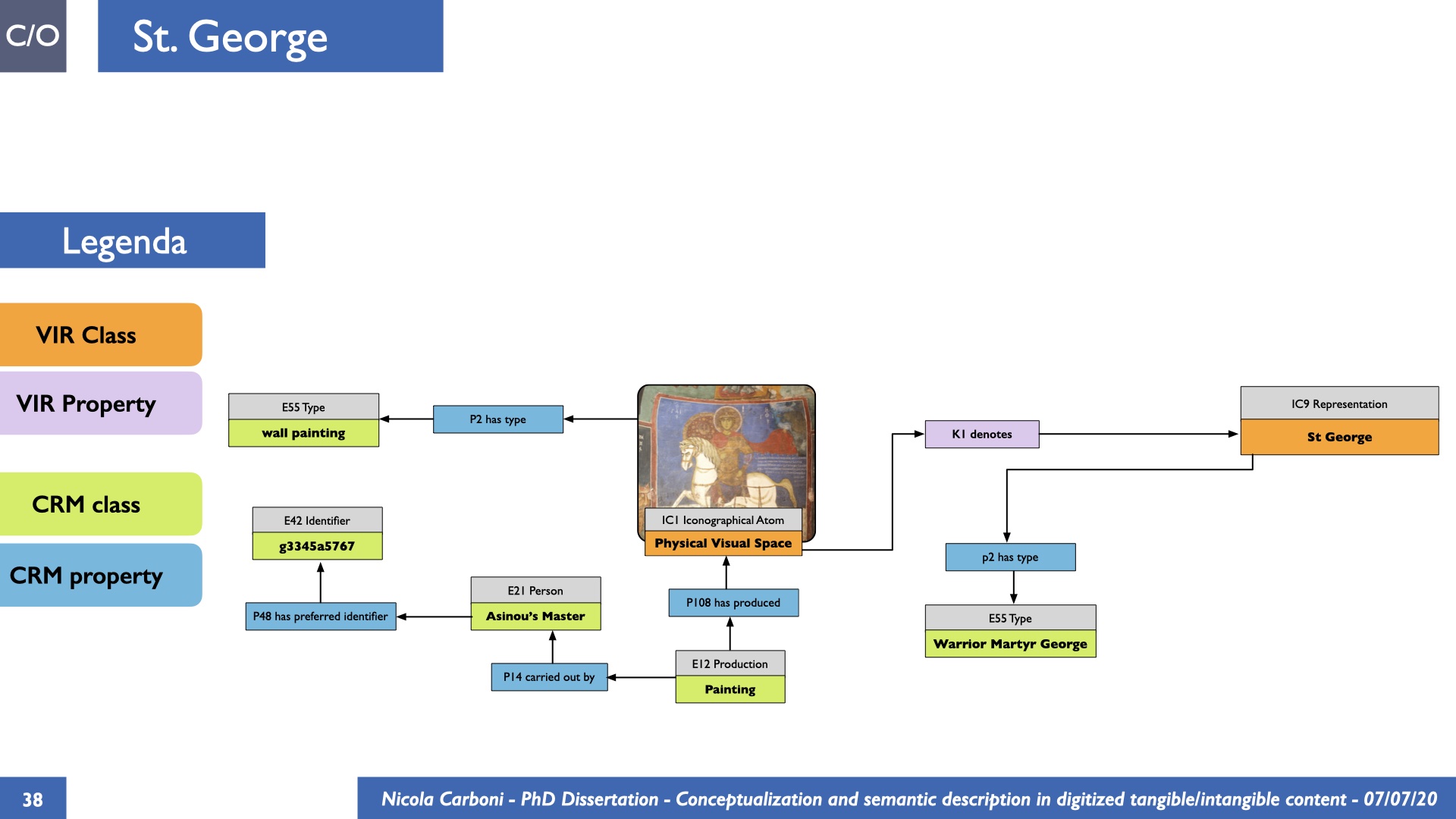

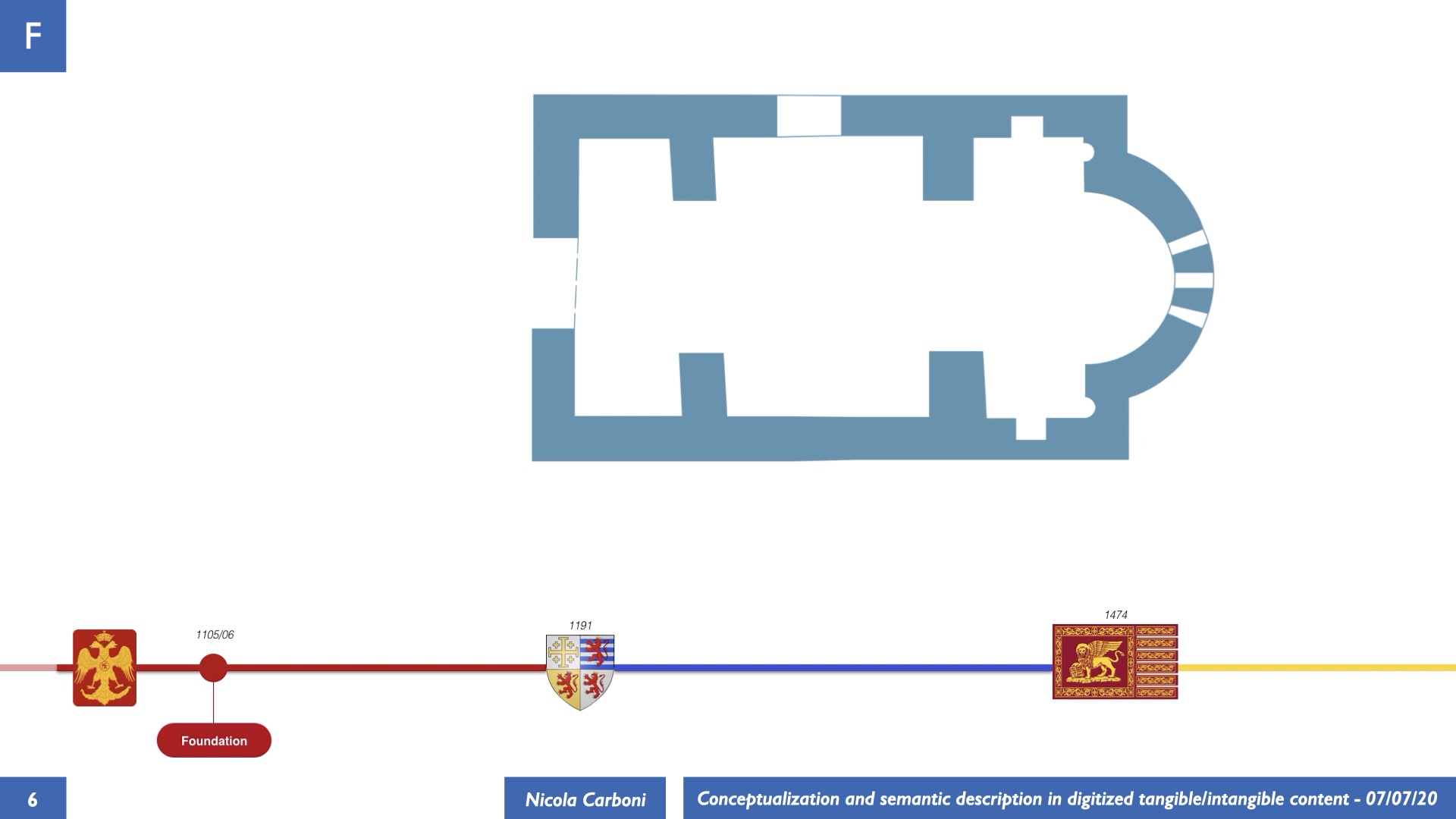


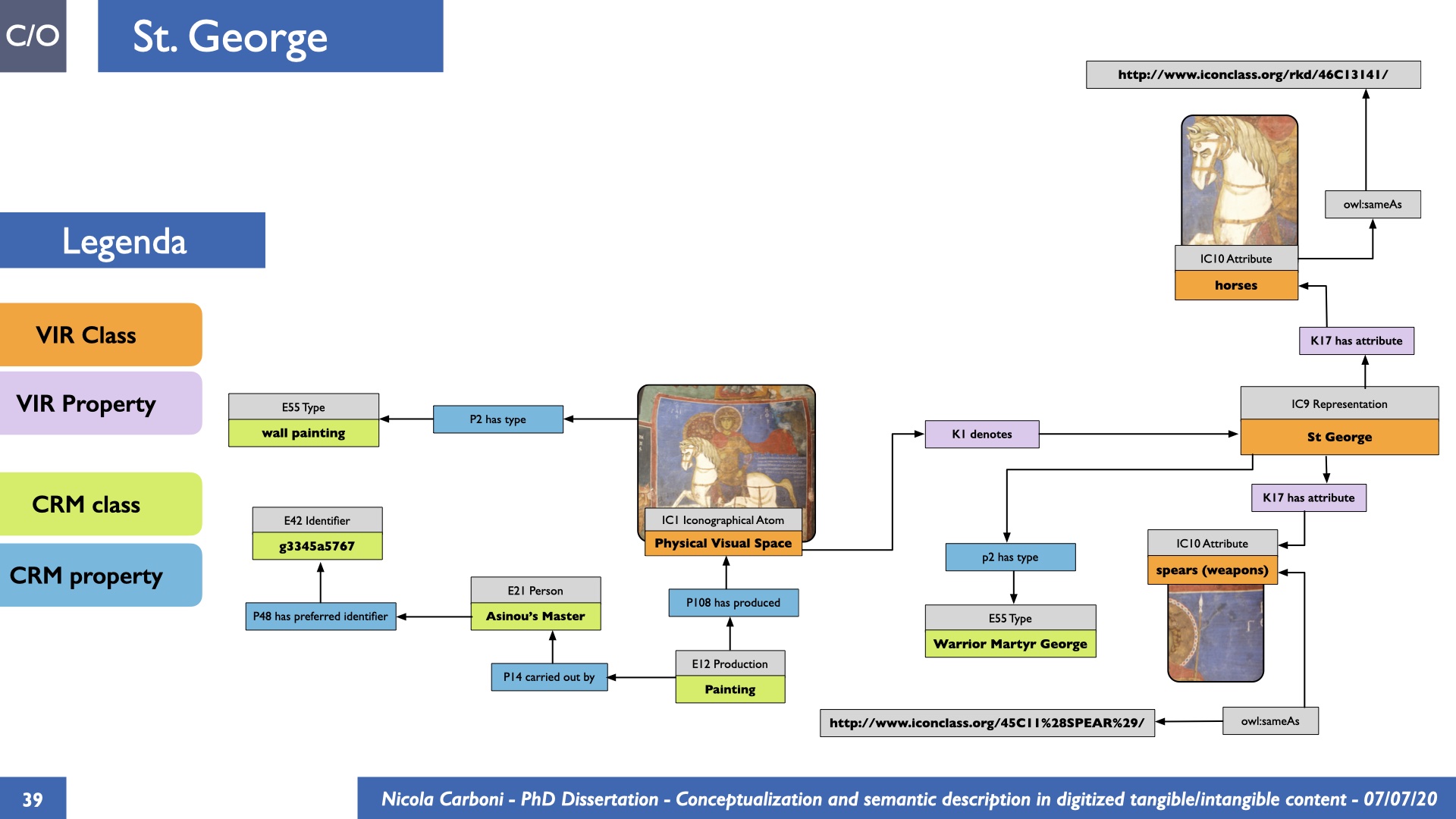


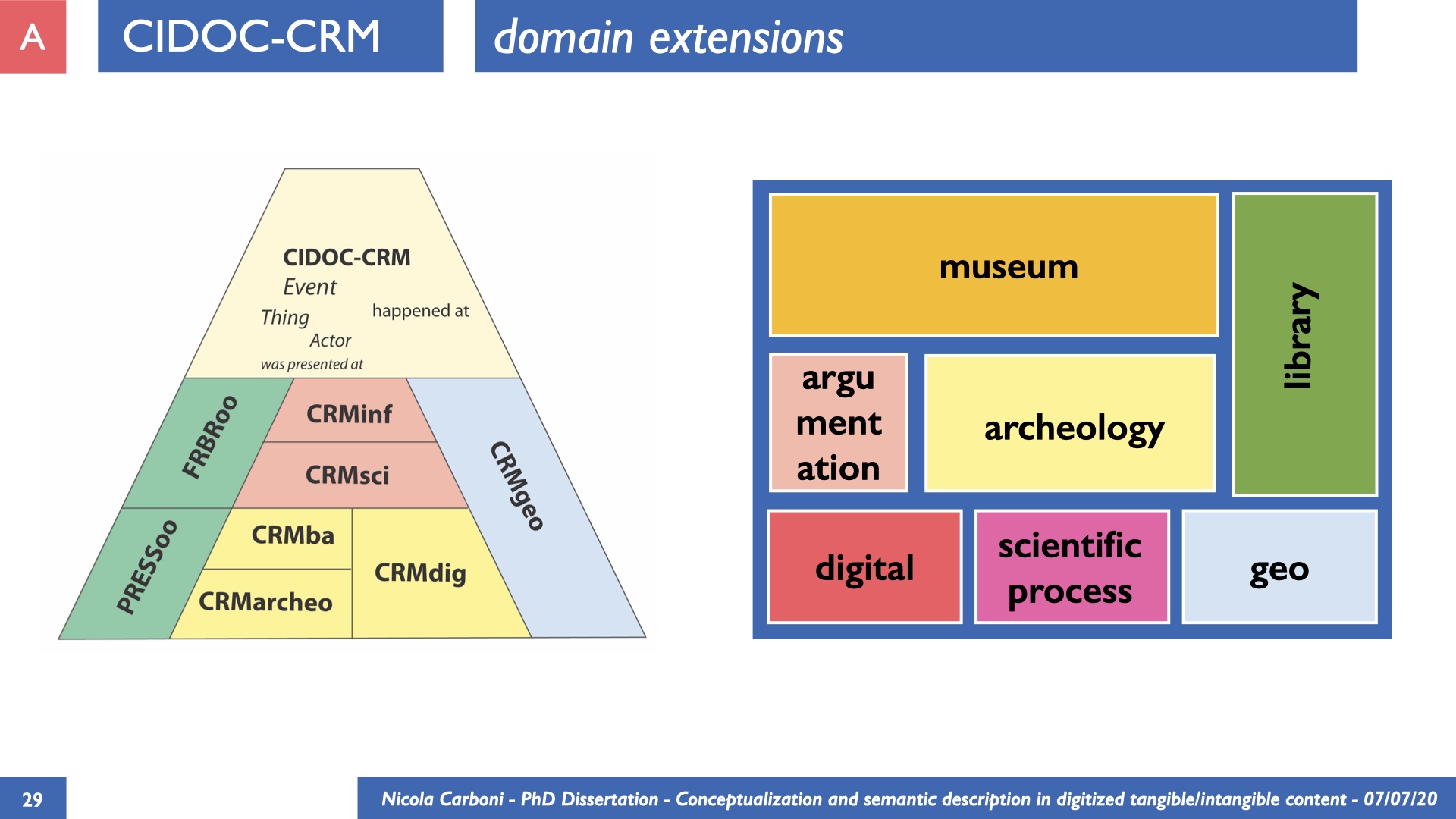


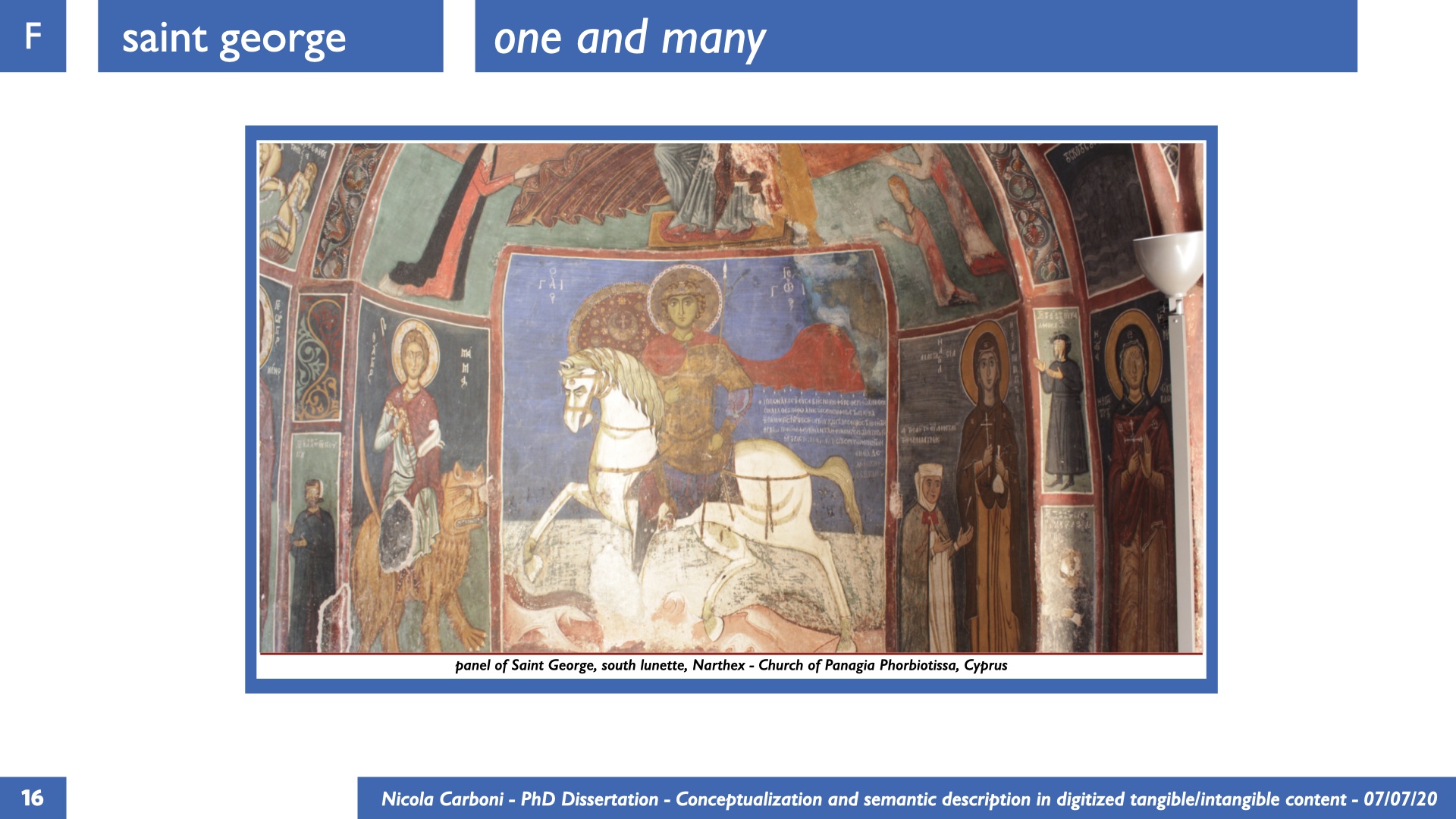



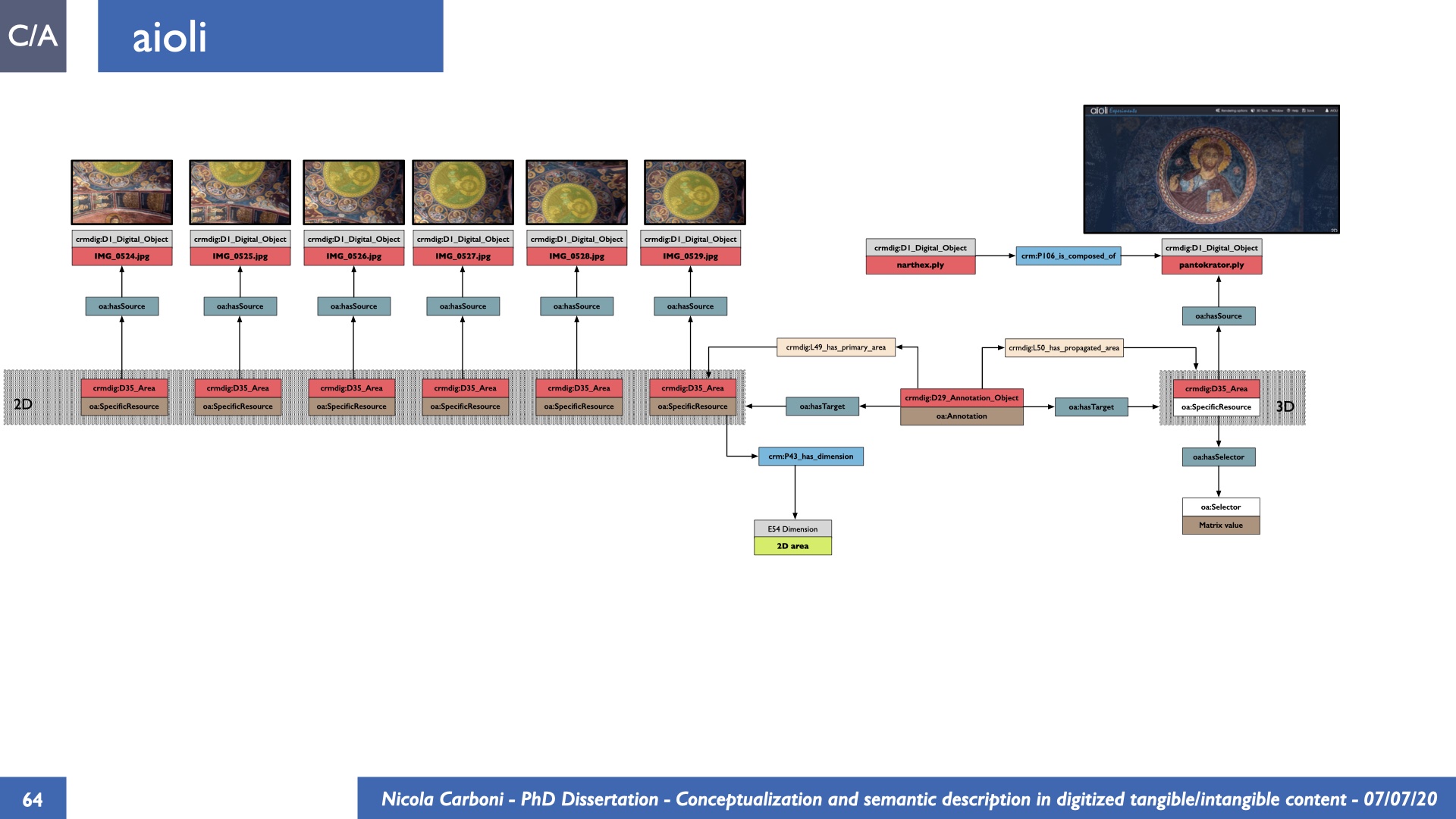
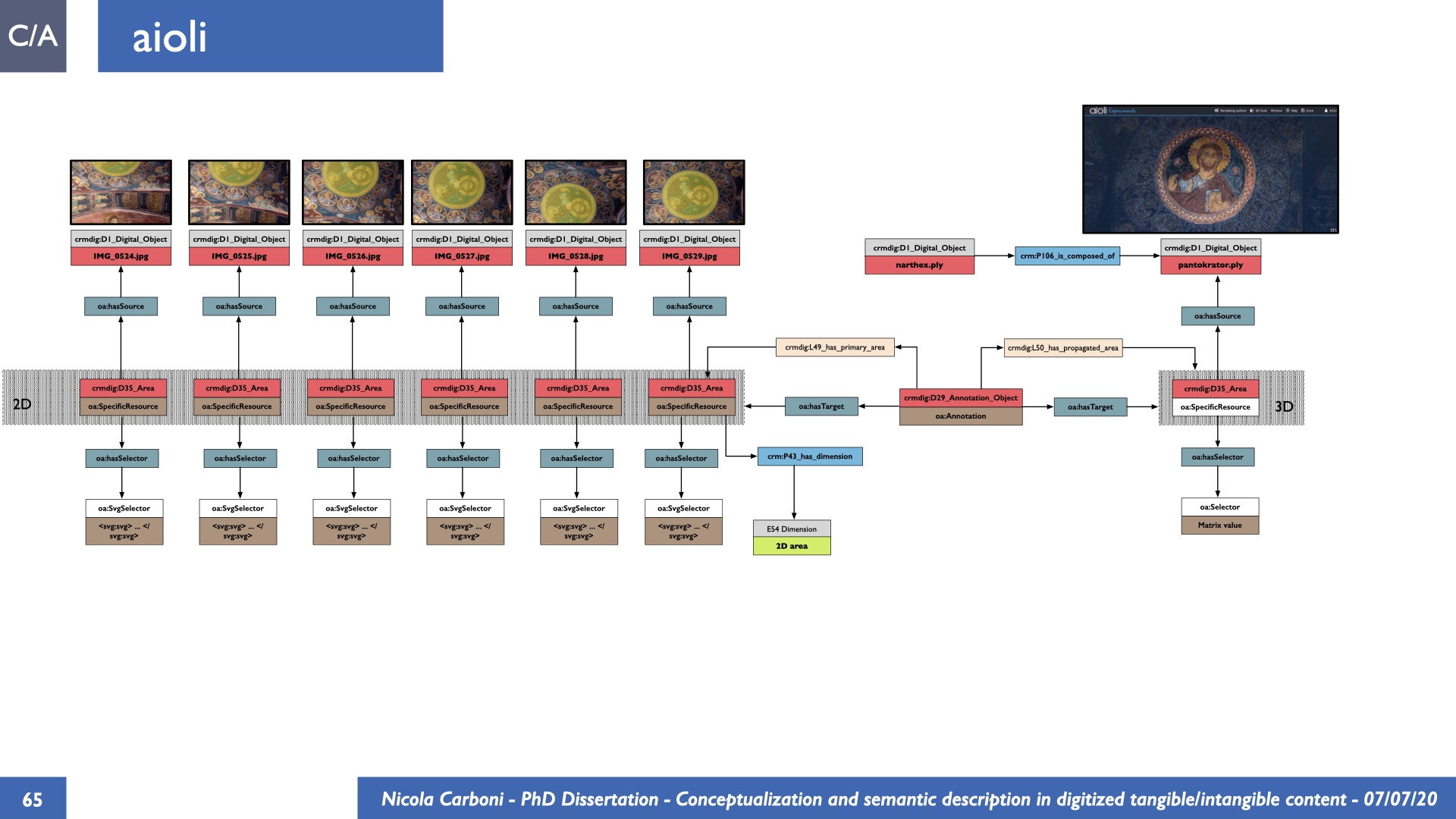


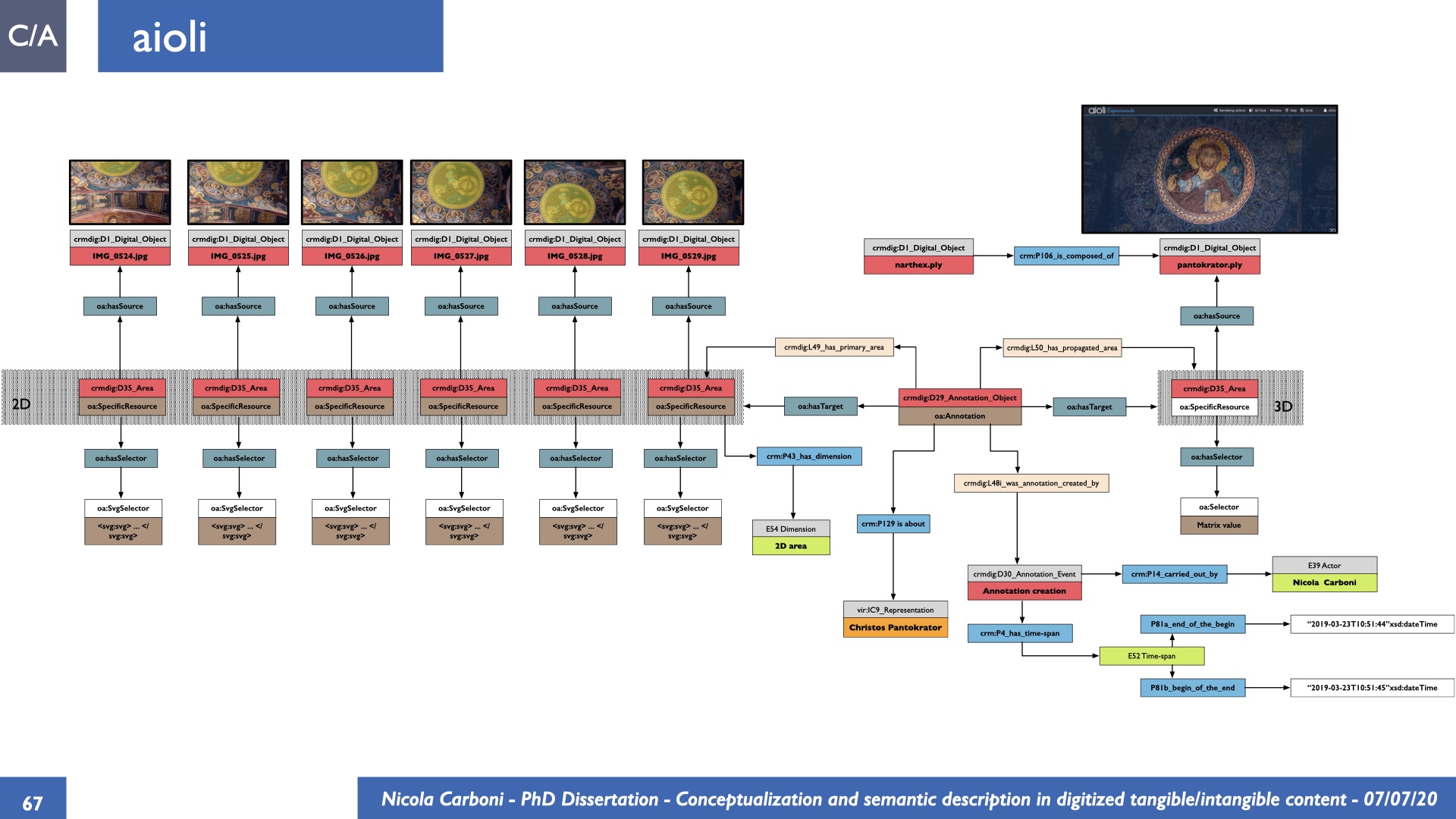
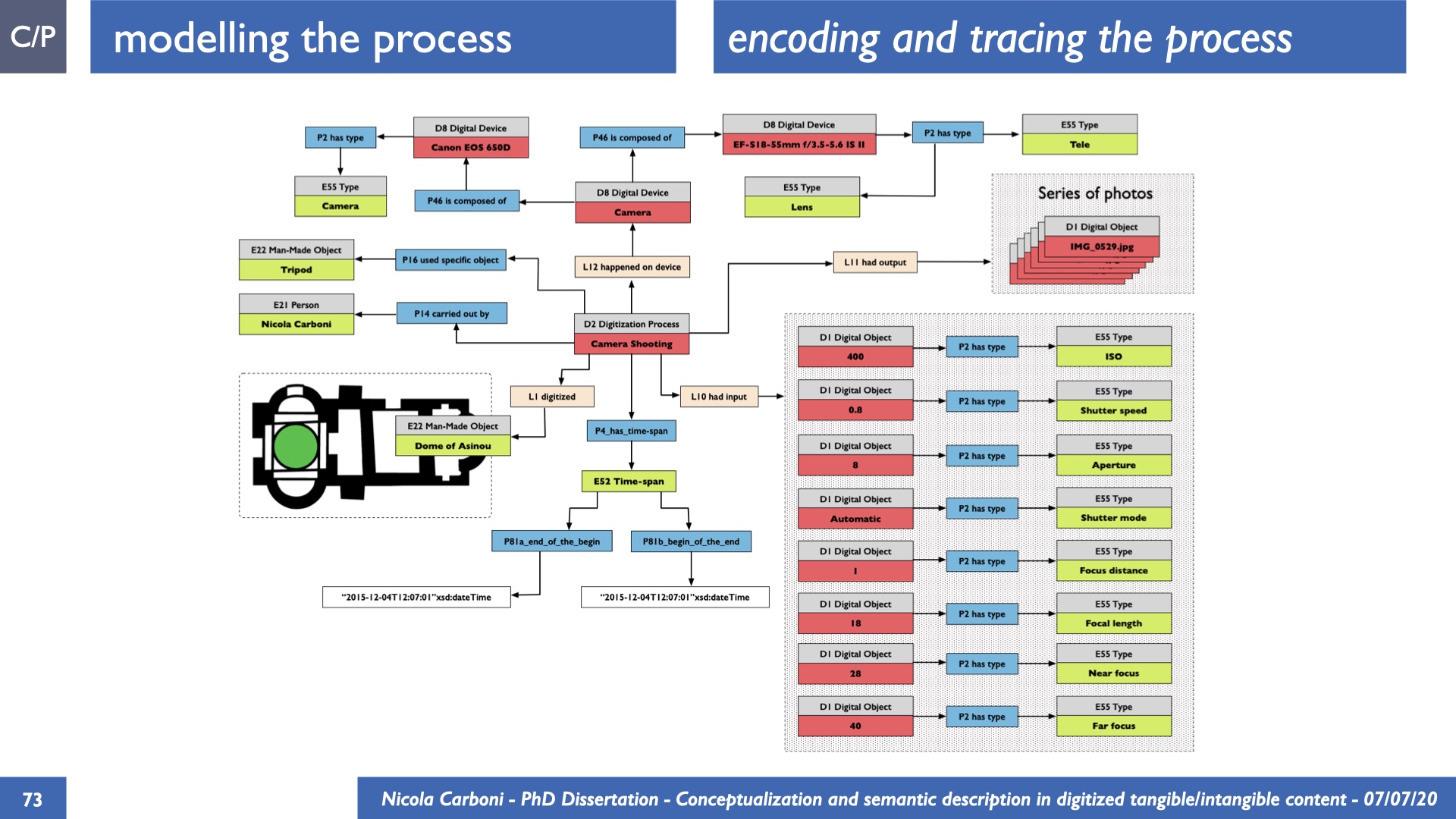
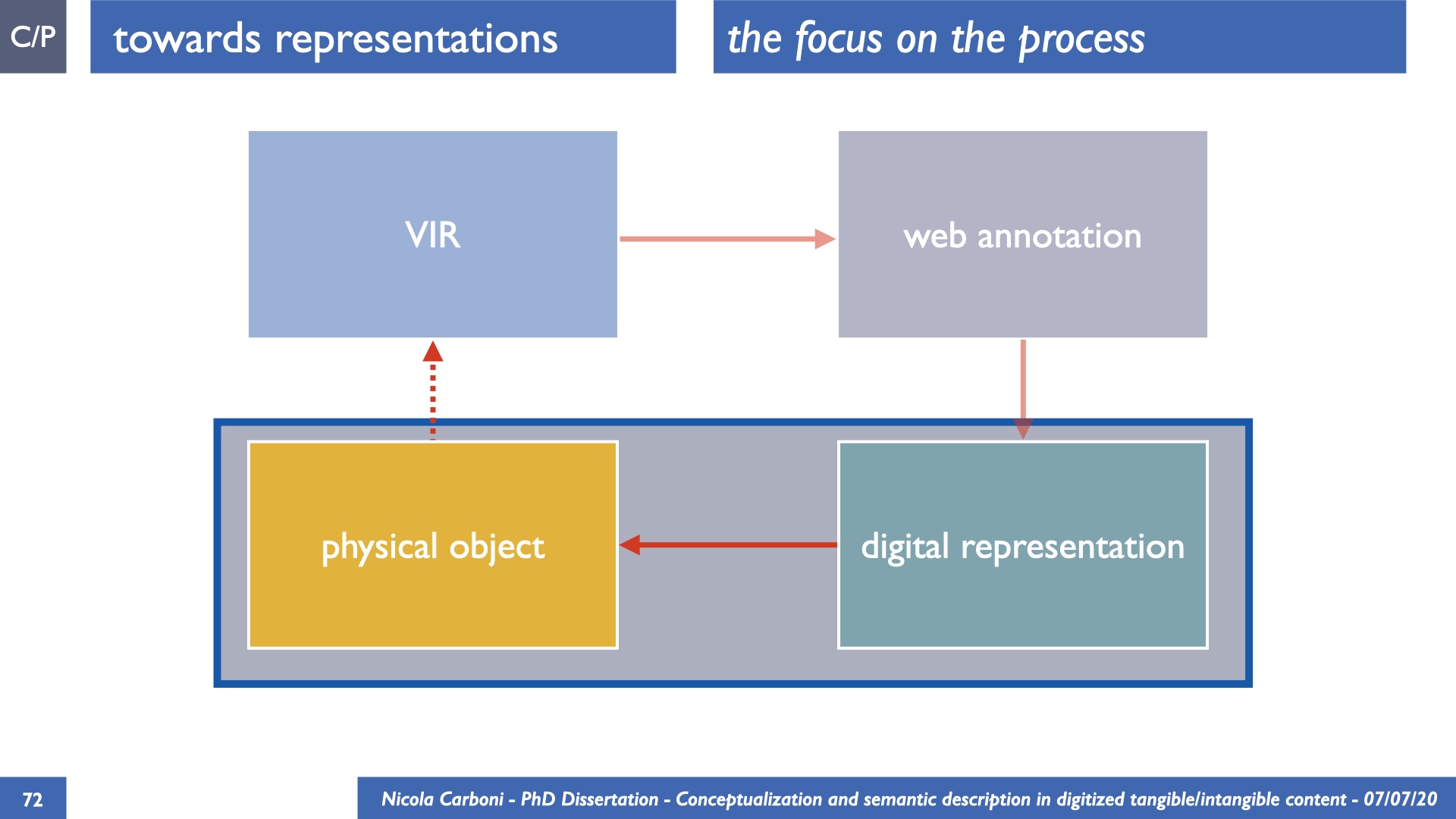
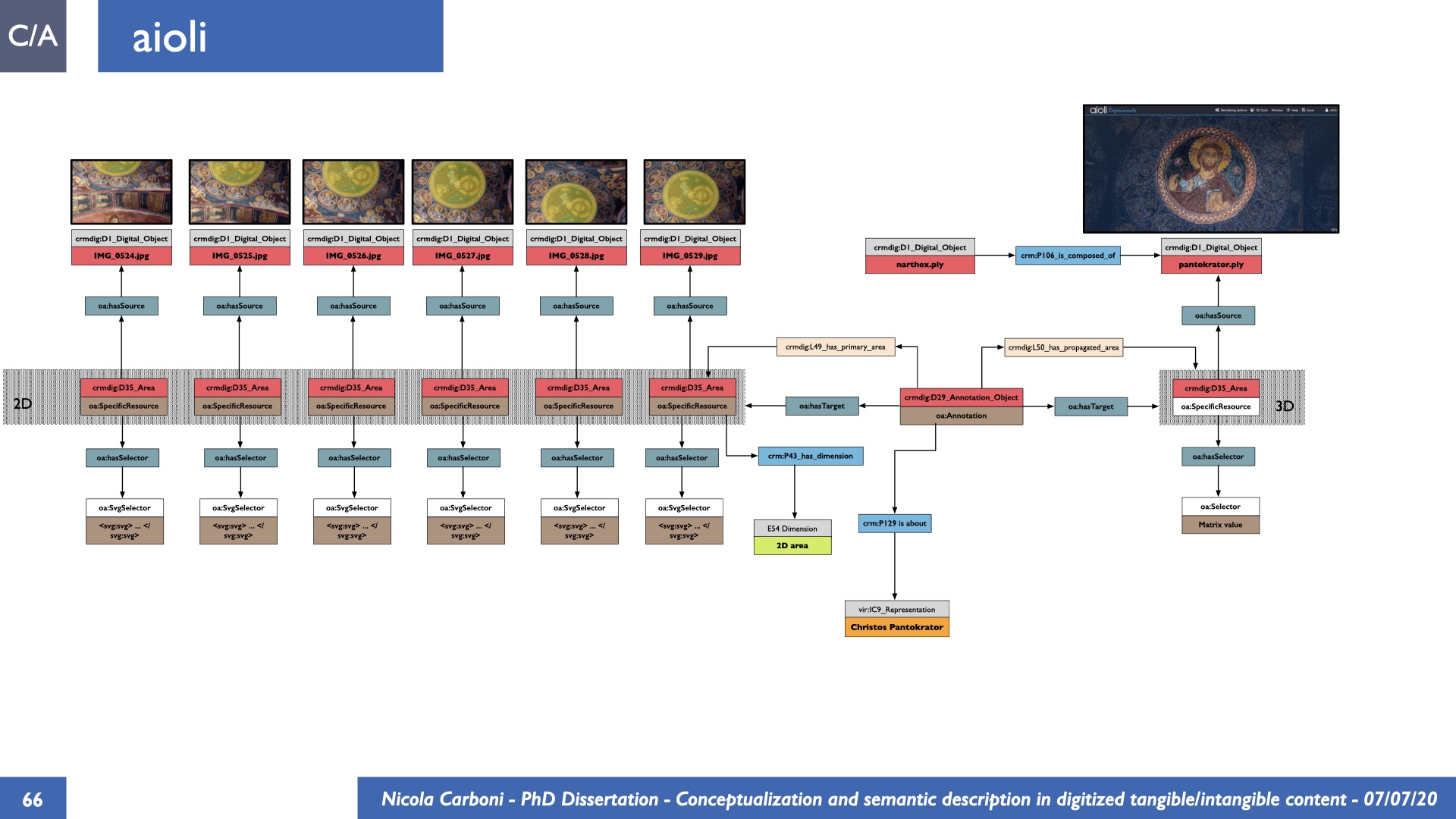

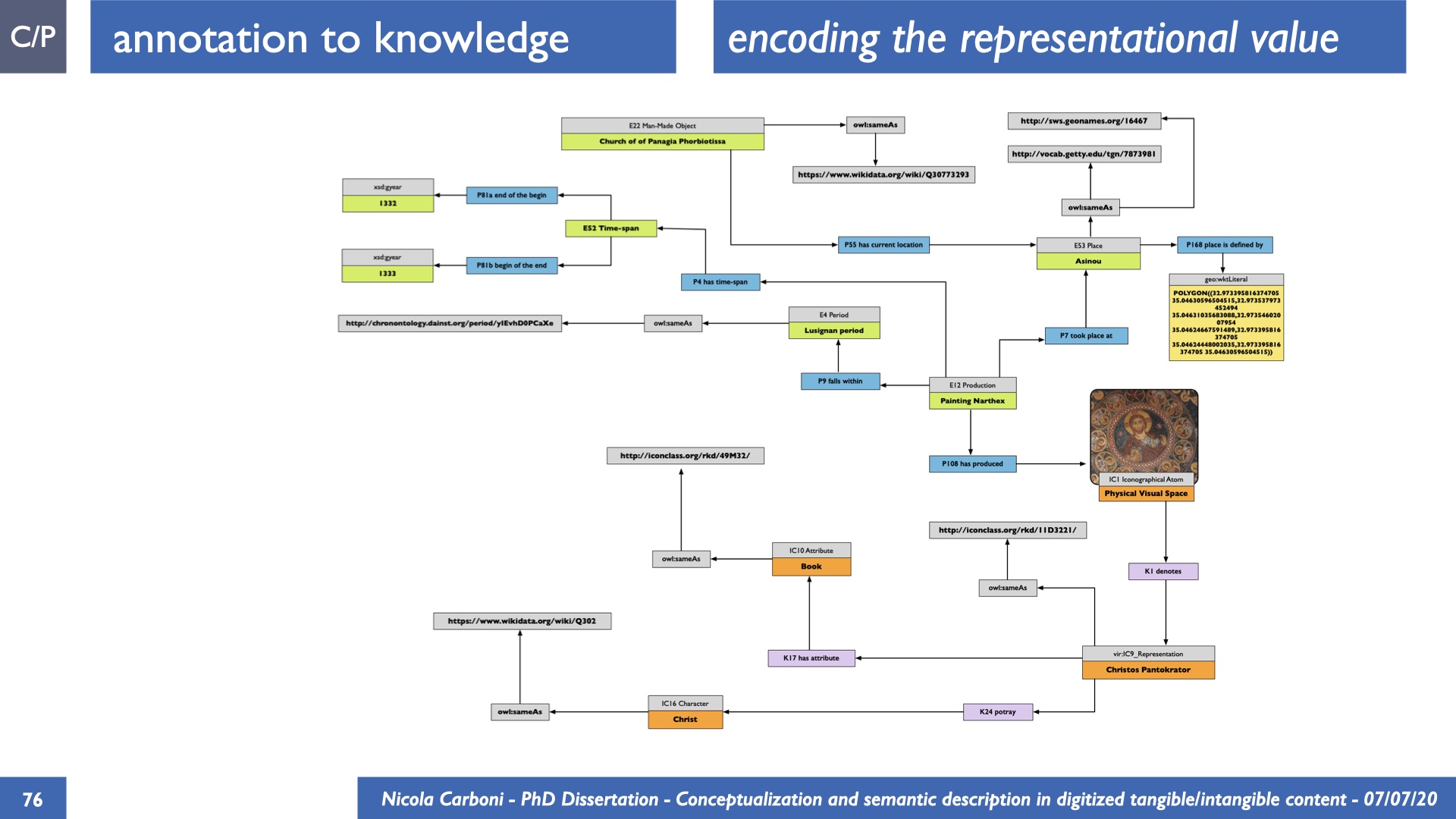


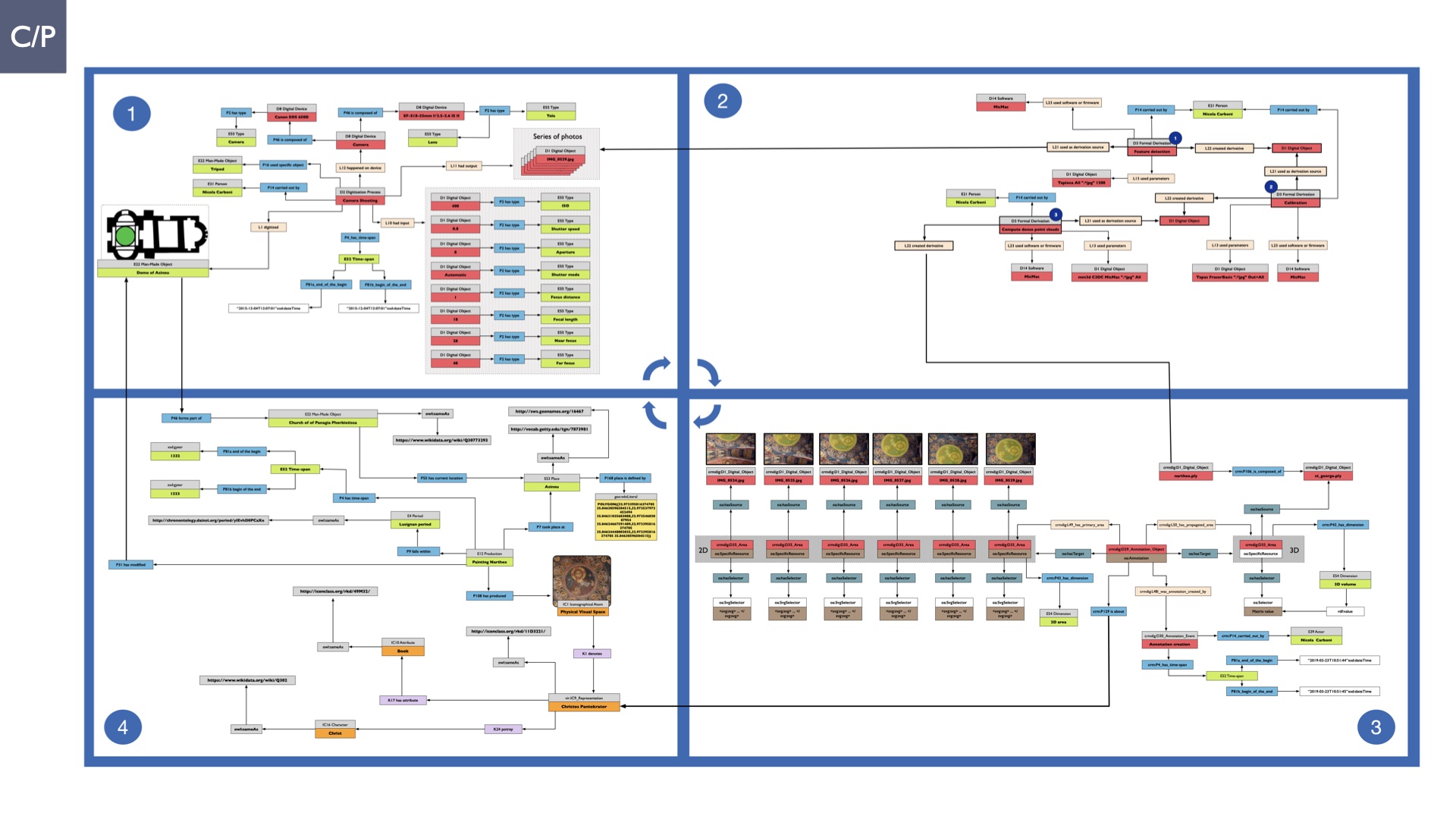

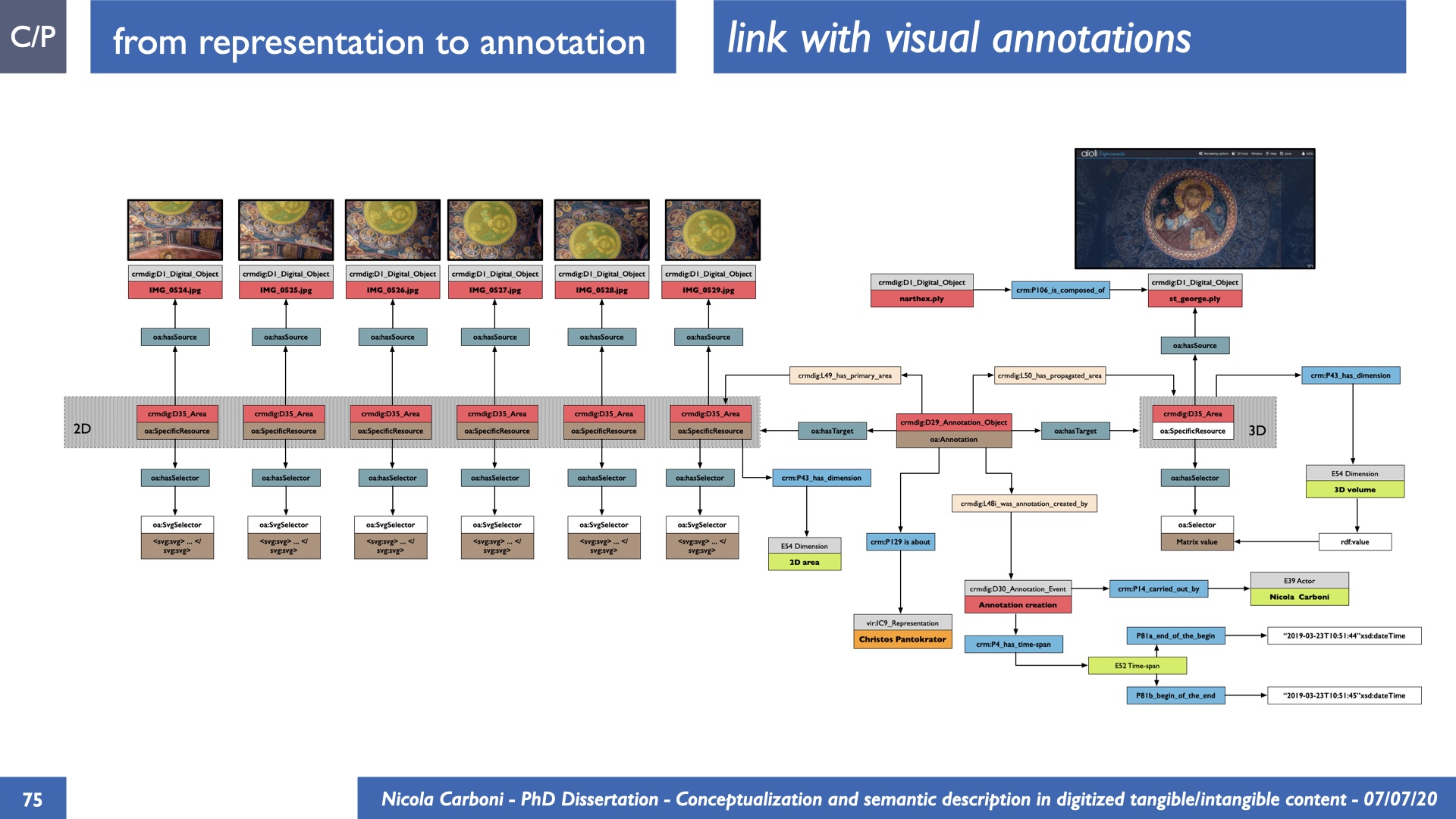
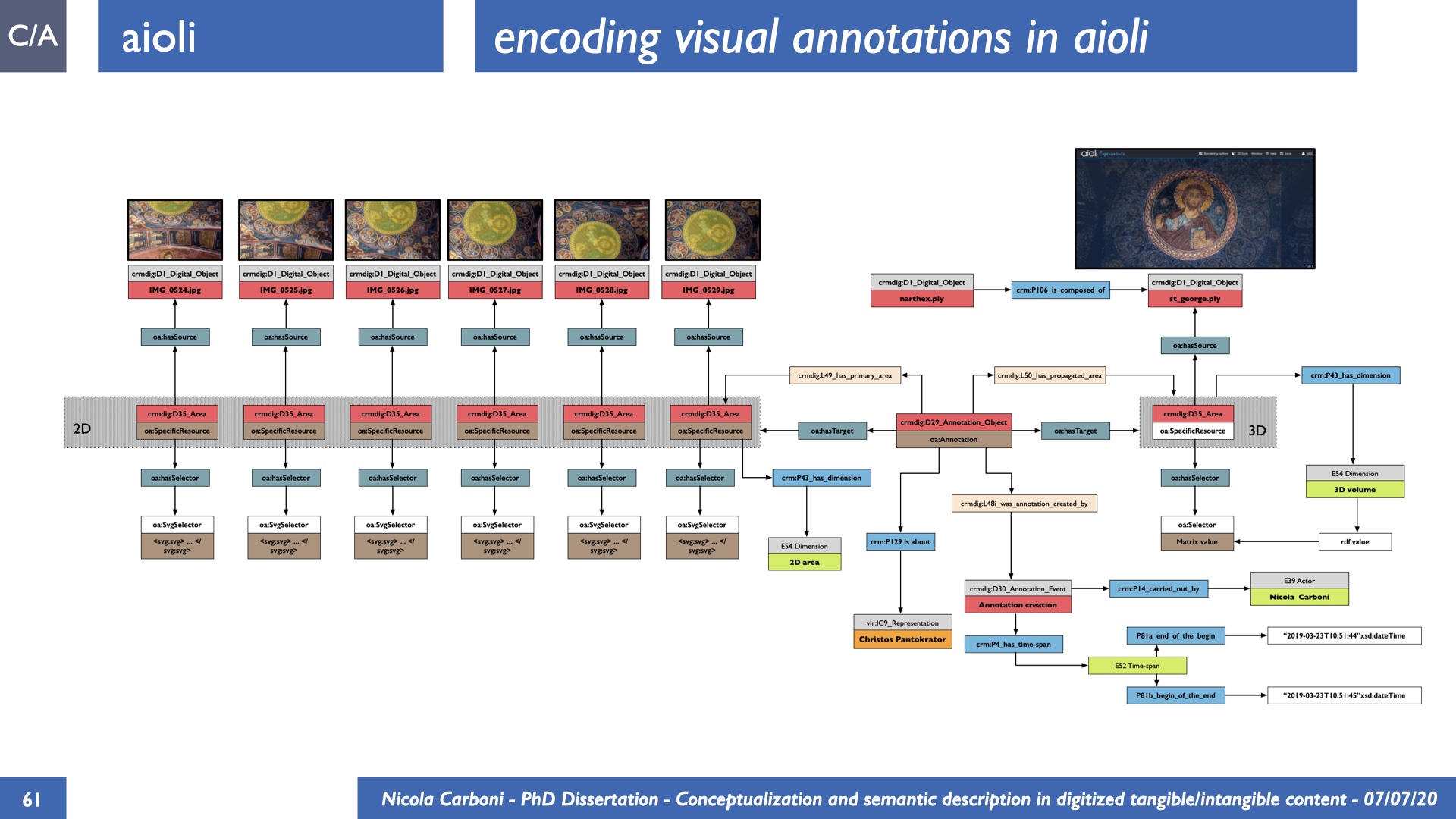
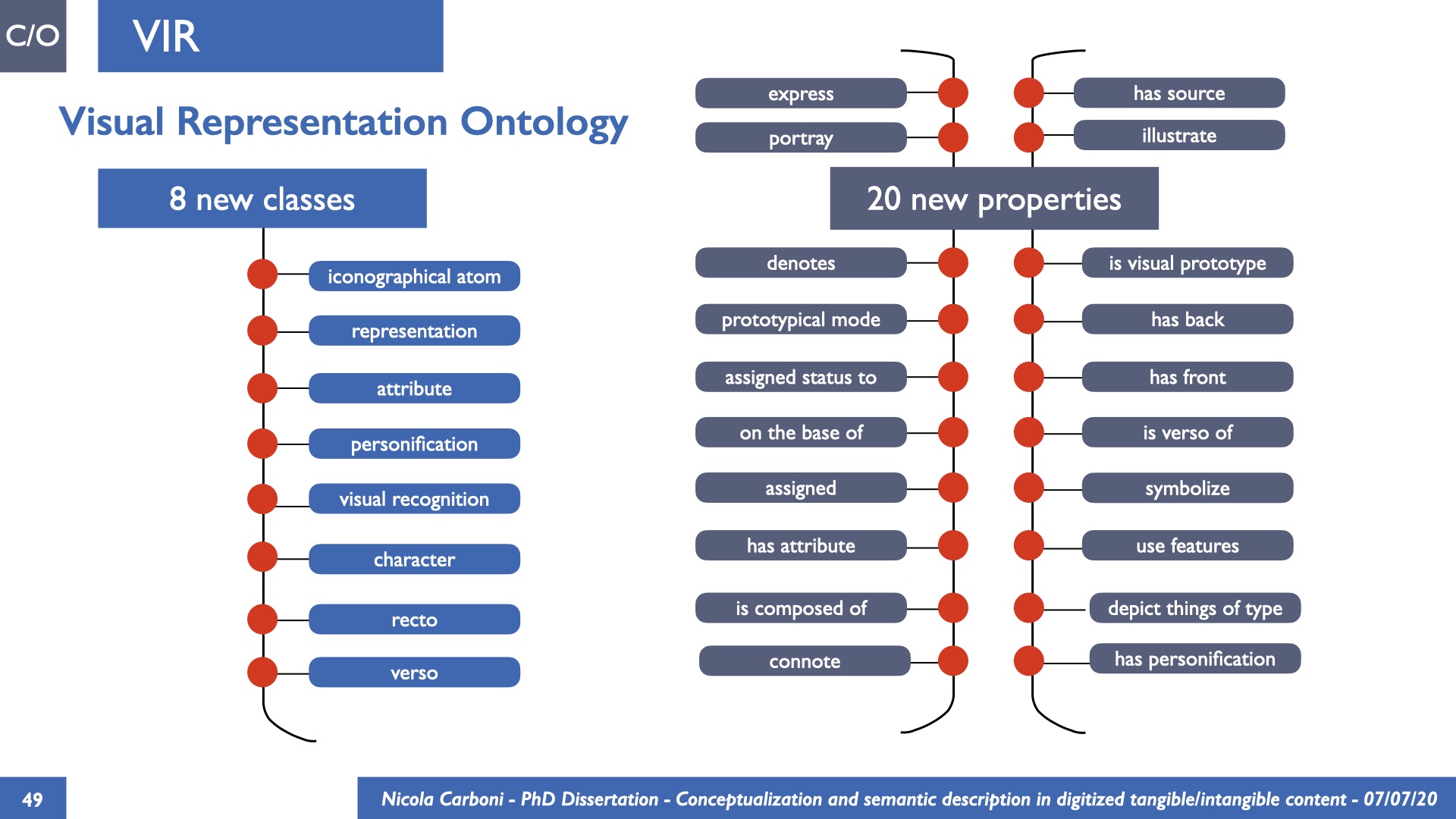
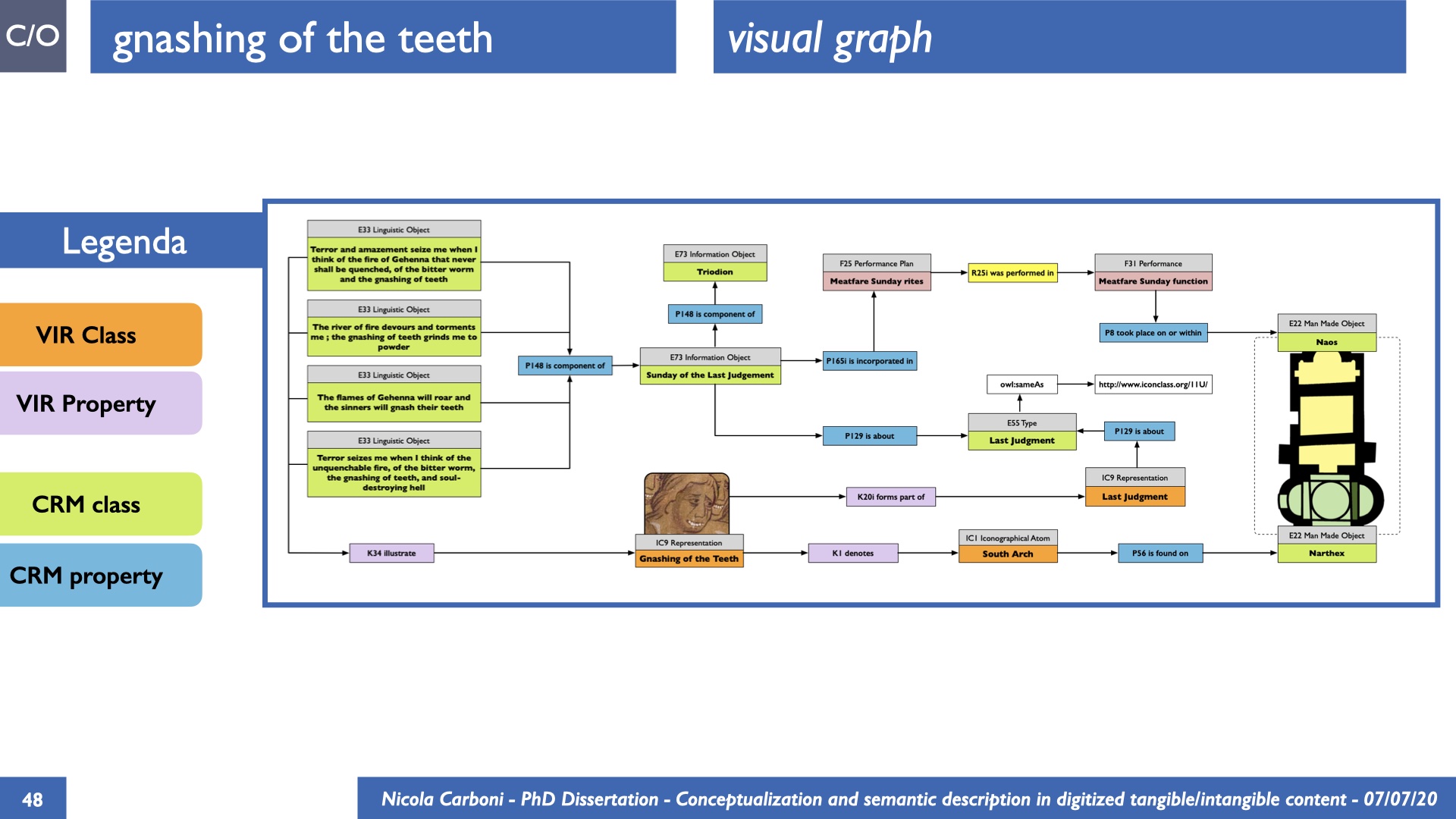
The dissertation investigates the visual interpretation of heritage objects and practices providing both a theoretical framework for understanding the process of meaning-assignment and a formal ontology for grounding propositions about visual objects into a constituent-based framework. The thesis starts its investigation from the theory of the perception of heritage, illustrating the nuclear components used in the process of interpretation as a way to understand how the meaning of the object is constructed. The dissertation advances a functional theory for the classification of the perceptual experience, correlating perceived signals to situations and physical things. The resulting structure helps to examine the meaning assignment of cultural content and to study the framing of both physical objects and performative actions in our everyday visual experience. The broad relevance of the framework in the context of the heritage practice is made explicit using pictorial examples of a famous subject of Eastern and Western art: Saint George. Instances of the visual representations of the saint are used to demonstrate both the function of the theoretical framework as well as its alignment with some iconographical representation theories in Art History. The framework is then used to guide the formalisation of an ontology, constructed as an extension of CIDOC-CRM to sustain recording of interpretations as statements about the constitutional elements within a visual representation. The result, tested with artworks coming from the church of Asinou, a small Byzantine foundation in Cyprus, demonstrates the capacity of the formal ontology to record the denotative and the connotative dimension of iconographical objects, unveiling their contextual meaning through the clarification of symbols, constituents, use within liturgical performances and historical influences. The ontology is further linked and harmonised with 3D data annotations structures, providing a framework of operation for using the ontology to classify visual annotations within a three-dimensional environment. Linked and harmonised with the W3C Web Annotation Data Model, the ontology is used to test the creation of semantic 3D annotations within the Aioli project. After having addressed the feasibility of the ontology to document the meaning-assignment in visual work, the dissertation further elaborates on the validity of the recorded information, specifically the one grounded on digital mediations such as photographs or three-dimensional hyper-realistic reconstructions. In order to tackle the problem, a provenance-based framework for the documentation of reality-based recording is presented. The framework provides a semantic formalisation for recording the different steps of a digitisation workflow in order to document the accuracy and reliability of the process as well as to frame the results as scholarly product and not mere visual artefact. The result is a single graph of object, practice and meanings linked together.